快速了解一个网络:YOLO, You Only Look Once (YOLOv2)
以下内容偏向于记录个人学习过程及思考,请审慎阅读。
背景
将 yolo v1 做的更好、更快、更强
核心思想
Better
Batch Normalization
引入 BN,对于网络收敛收益显著,涨掉明显,且去除了 drop out 正则操作
这一操作也带来了超过 2% 的涨点。
High Resolution Classifier
之前的 SoTa detection 方法一般使用的都是基于在 ImageNet 上预训练的分类网络,基于 AlexNet 的骨干网络输入大小一般都小于 256 x 256。如 yolo v1 是基于 224 x 224 的输入进行分类骨干网络的预训练,再基于 448 x 488 的输入做检测。
作者认为这一操作会让网络需要在新的分辨率同时学会分类和检测,不利于网络学习。
因此对于 yolo v2,作者直接使用 448 x 488 的输入在 ImageNet 上预训练分类网络 10 个 epoch,让网络提前适应高分辨率下的检测。
这一操作也带来了 4% 左右的涨点。
Convolutional With Anchor Boxes
之前 yolo v1 是将输入分为 7 x 7 个 grid cell,每个 grid cell 预测 2 个框用来检测。
但是之前的框没有任何的 scale 或者是比例限制,任由网络自己学习、野蛮生长,这会导致网络初期的稳定性比较差、很难收敛。
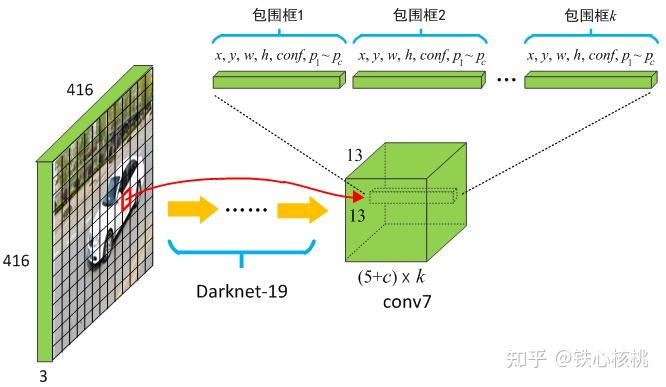
yolo v2 采用了 Anchor Boxes,根据数据集 bounding box 的分布特性,人为设定一些先验的、固定比例和大小的框,让网络只预测相对 anchor box 的 offset,这会让训练任务大大简化。
作者特别提到在训练过程中会把输入图像大小从 448 x 488 缩小为 416 x 416,这样在下采样 32 倍之后可以得到 13 x 13 的 feature map。作者希望最终 feature map 的大小是奇数的,这样正中间就会仅有1个cell,作者认为这对于图像中的大物体检测比较有帮助。
另外,之前 yolo v1 是每个 grid cell 负责预测类别,在 yolo v2 中变为了对于每个 anchor box 预测类别。
参考文章 目标检测那点儿事——更好更快的YOLO-V2 的两张示意图
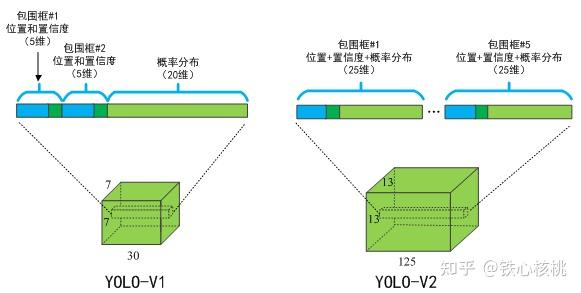
anchor box 的做法让 yolo v2 的 recall 涨点较多,precision 仅有轻微掉点。
Dimension Clusters
作者提到在使用 anchor box 时,第一个遇到的问题就是设置 anchor box 的 dimension,如果设置的比较好那么网络学起 offset 来也会非常的容易。
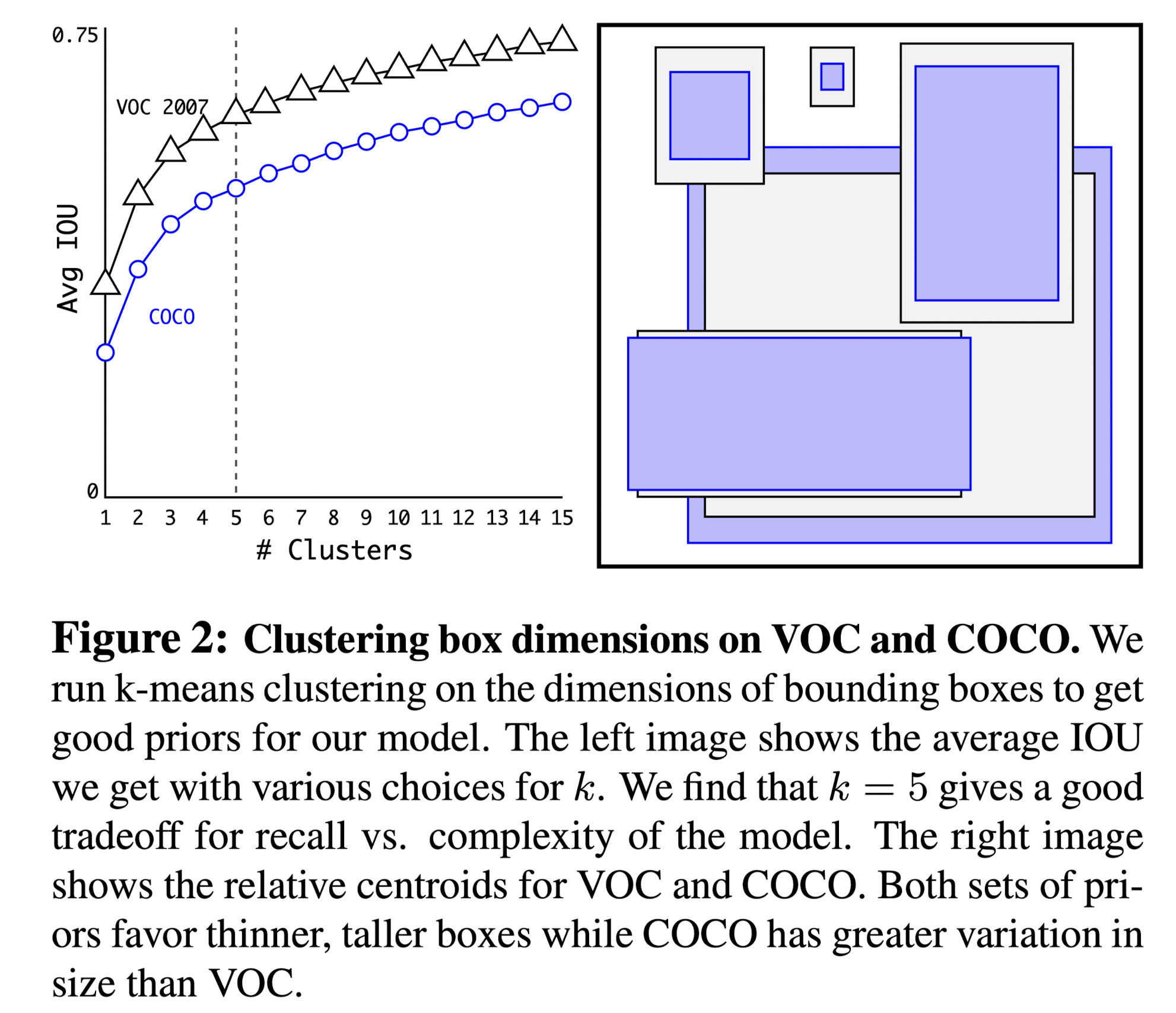
为了更好的进行 anchor box 的设置,作者对于训练集的 bounding box 进行来 k-means 聚类。距离方面使用 (1 - iou),防止使用欧式距离大框产生的误差远大于小框。
作者认为分为 5 类可以达到比较好的 recall 和 complexity 的平衡,以下是 voc 数据集和 coco 数据集使用 k-means 聚类后的分类结果,图中的示意框是与分类结果中心点 iou 最大的框。
Direct location prediction
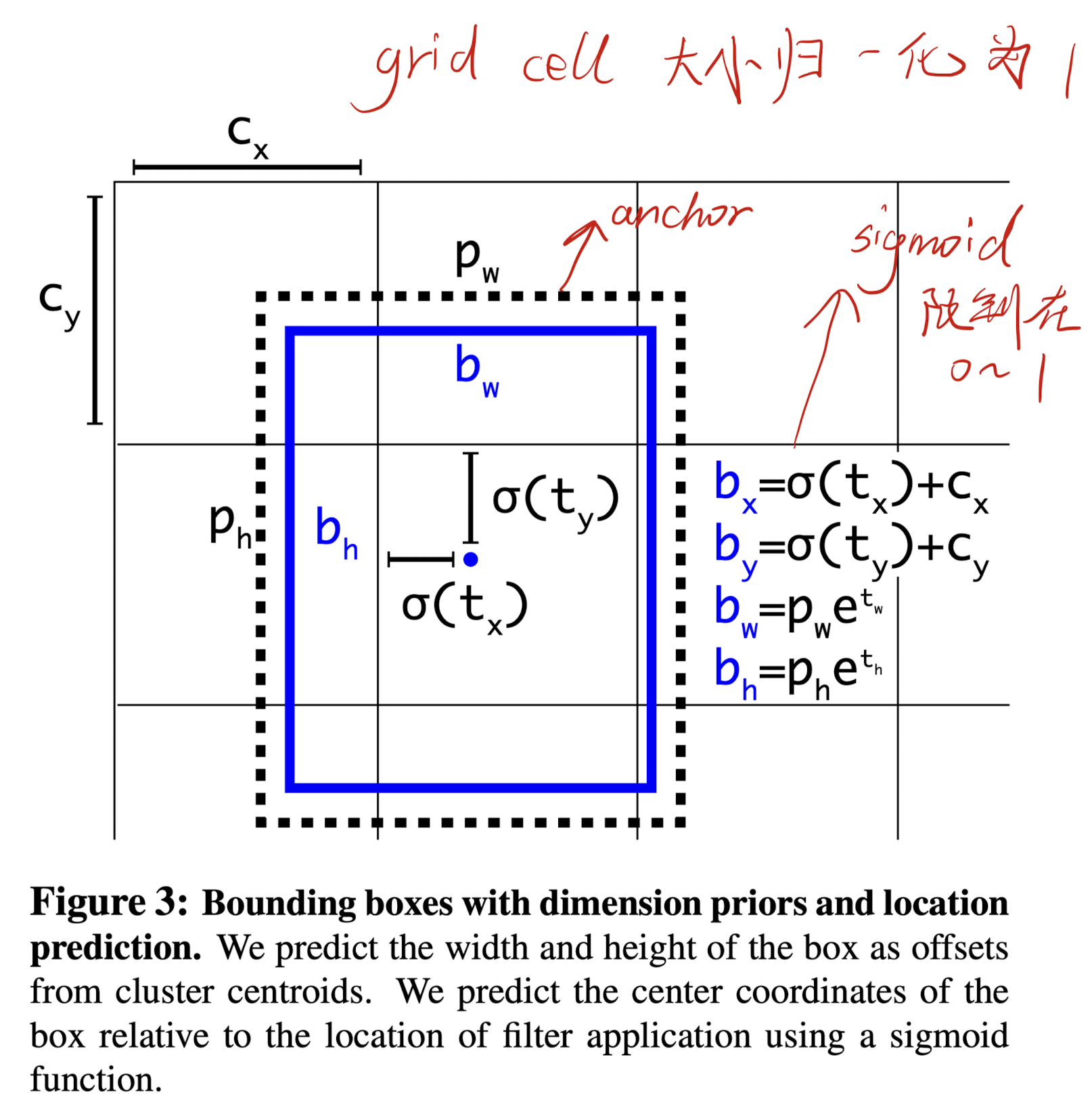
在 yolo v1 中,预测的框的位置是相对于 grid cell 的 offset,但其实并没有限制,因此网络初期预测框可能是全图乱窜、野蛮生长的状态,这也会使得网络的训练非常不稳定。
在 yolo v2 中,网络会预测框相对于 anchor box 左上角的偏移量,并且用 sigmoid 函数限制在 0 - 1( grid cell 的大小也归一化到 0 - 1 ),这就大大限制住了模型的预测范围,利于网络训练的稳定性。
Fine-Grained Features
为了获得较浅深度 feature map 的特征(感受野较小,利好小目标检测),作者搞了一个 passthrough 的结构,将浅层的特征拆分后与深层的特征 concat 叠加起来进行检测。
【精读AI论文】YOLO V2目标检测算法 视频中对于 passthrough 结构提供了 2 个比较好理解的图。
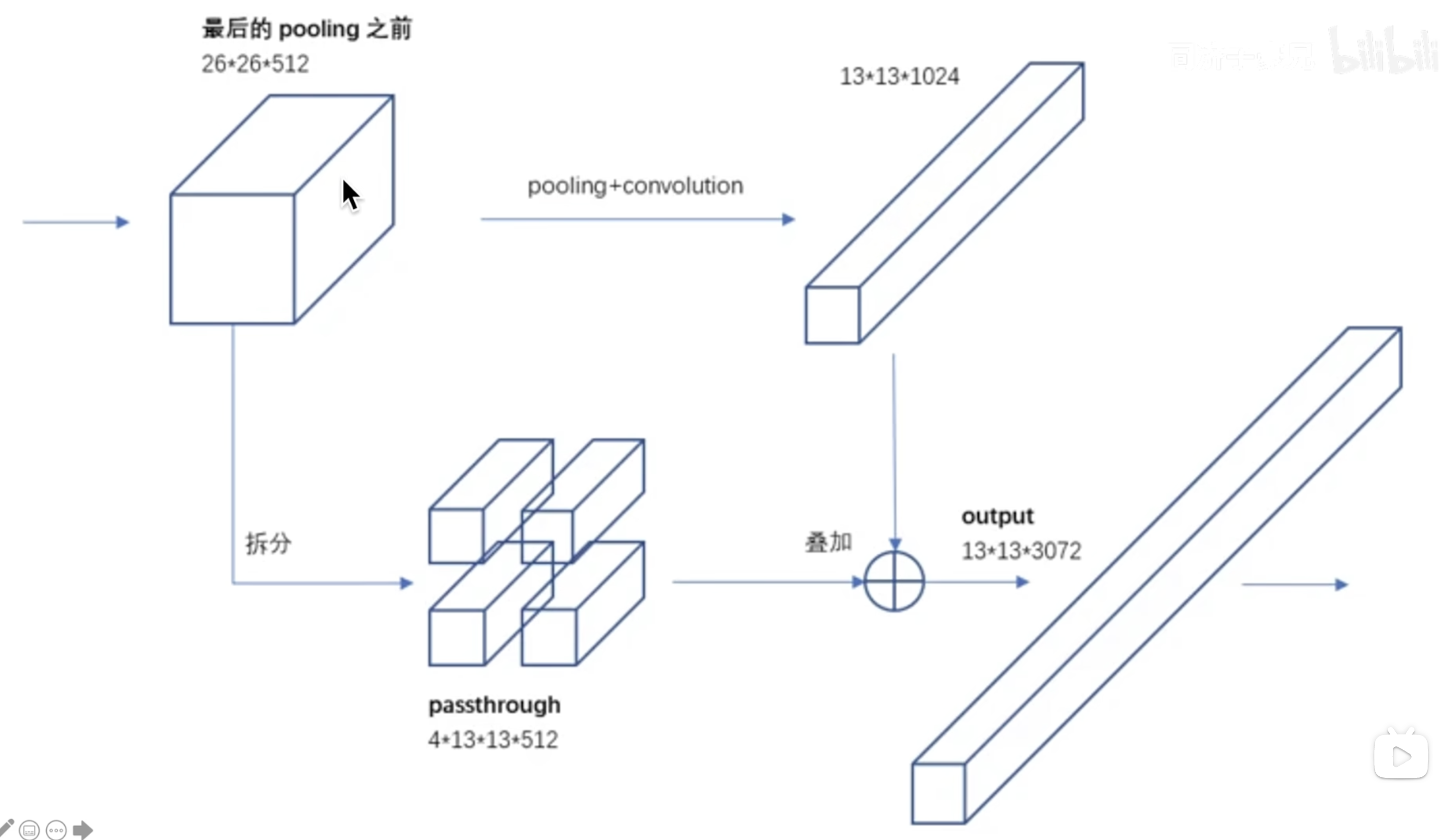
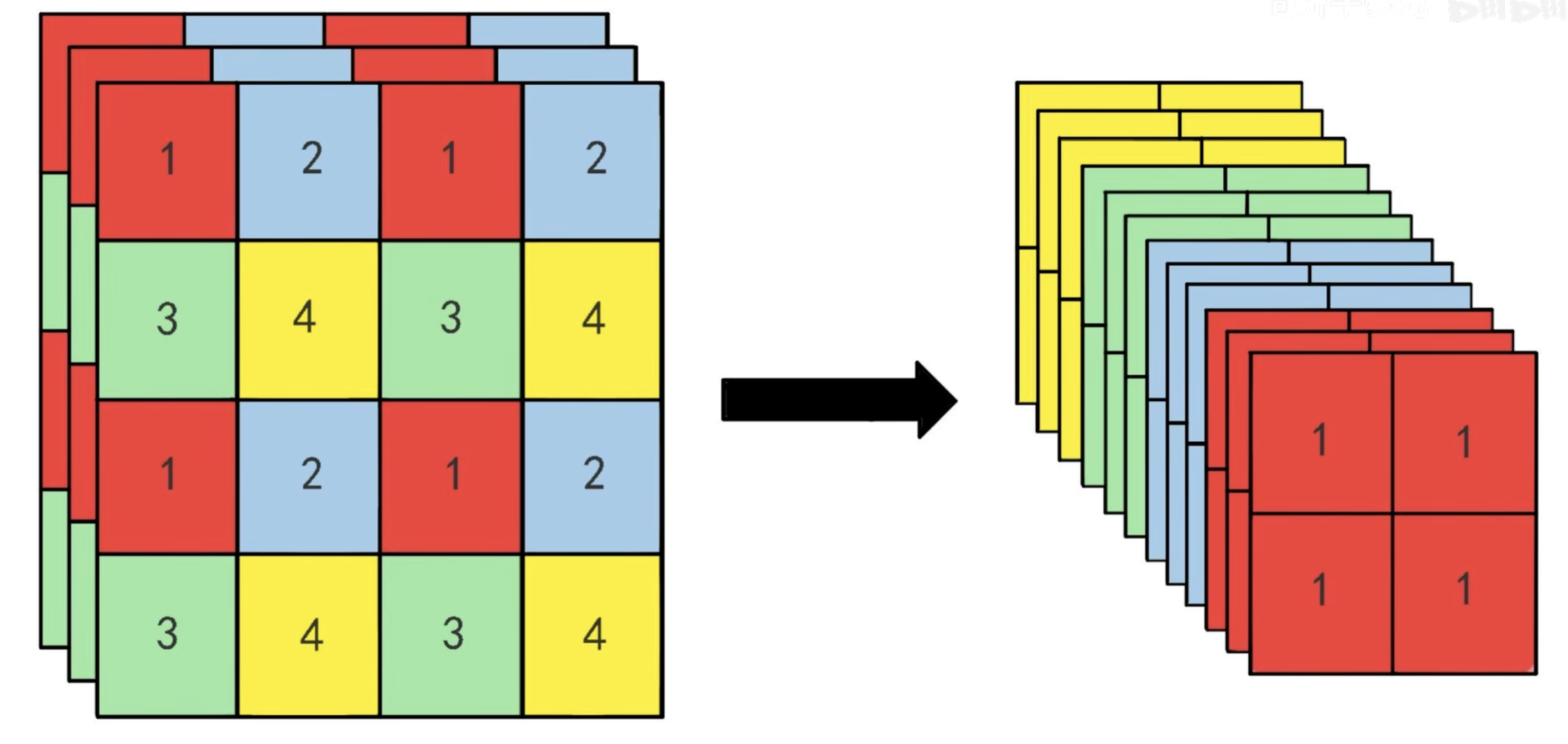
Multi-Scale Training
yolo v2 原始的输入为 448 x 448,加入 anchor box 后将输入变成了 416 x 416(原因见上)
为了网络可以对不同大小的图片都有比较好的检测能力,这里作者每 10 个 batch 会随机选择一个新的图像 size,强迫模型学会不同的输入图像大小。
因为网络是 32 倍下采样,因此这里作者将输入的不同 size 都设置为 32 的倍数,并将网络 resize 适应对应的输入 size 进行训练(通过 global average pooling 实现)。这样可以让网络对于不同大小的图像都有比较好的检出性能。
Faster
Darknet-19
作者认为 VGG-16 作为 backbone 比较复杂,网络推理速度较慢。yolo v1 使用了一个自定义的 Googlenet,比 VGG-16 快,但是有少量的掉点。
作者在 yolo v2 中提出了一个 Darknet-19 的网络,速度快的同时效果也有保证。
Training for classification
作者在 ImageNet-1000 上做训练,并使用了多种数据增强的方案。
Training for detection
做目标检测时,将上述网络的最后一层去除,并用新的卷积层代替,预测检测框相关信息。
Stronger
作者将分类和检测混合训练,对于检测正常反向传播 loss;对于分类则只反传分类相关的 loss。
Hierarchical classification
但混合训练为作者带来一个问题,ImageNet 的类别非常细致,狗的种类都有很多,而 COCO 中可能只有 dog。所以混合训练时不能将这些类别一起作 softmax,这会使网络 confused。
因此作者建立了一个类别的等级 tree,按照类别的等级进行建树和分类,然后只对每个等级内部作分类的 softmax。
参考文章 目标检测那点儿事——更强的YOLO-9000 的示意图
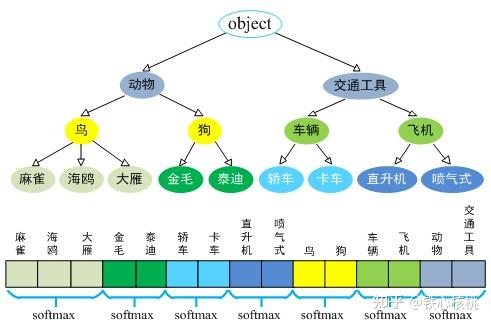
Joint classification and detection
当网络看到一个检测任务的图,网络正常反向传播loss。对于其中的分类,因为没有更细致的类别,loss就只考虑树中相对高层的类别。
当网络看到一个分类任务的图,只反向传播分类相关的loss。对应找概率最大的预测该类别的anchor box即可,在对应的类别等级树上计算loss。
因此可以在 coco 数据集中检测细致的类别,在 ImageNet 中检测大类的框。
Pipeline
原 yolo v2 论文中并没有提供网络的结构图。
3.1 YOLO系列理论合集(YOLOv1~v3) 视频中,根据 yolo v2 的代码提供了一个比较好的结构图。
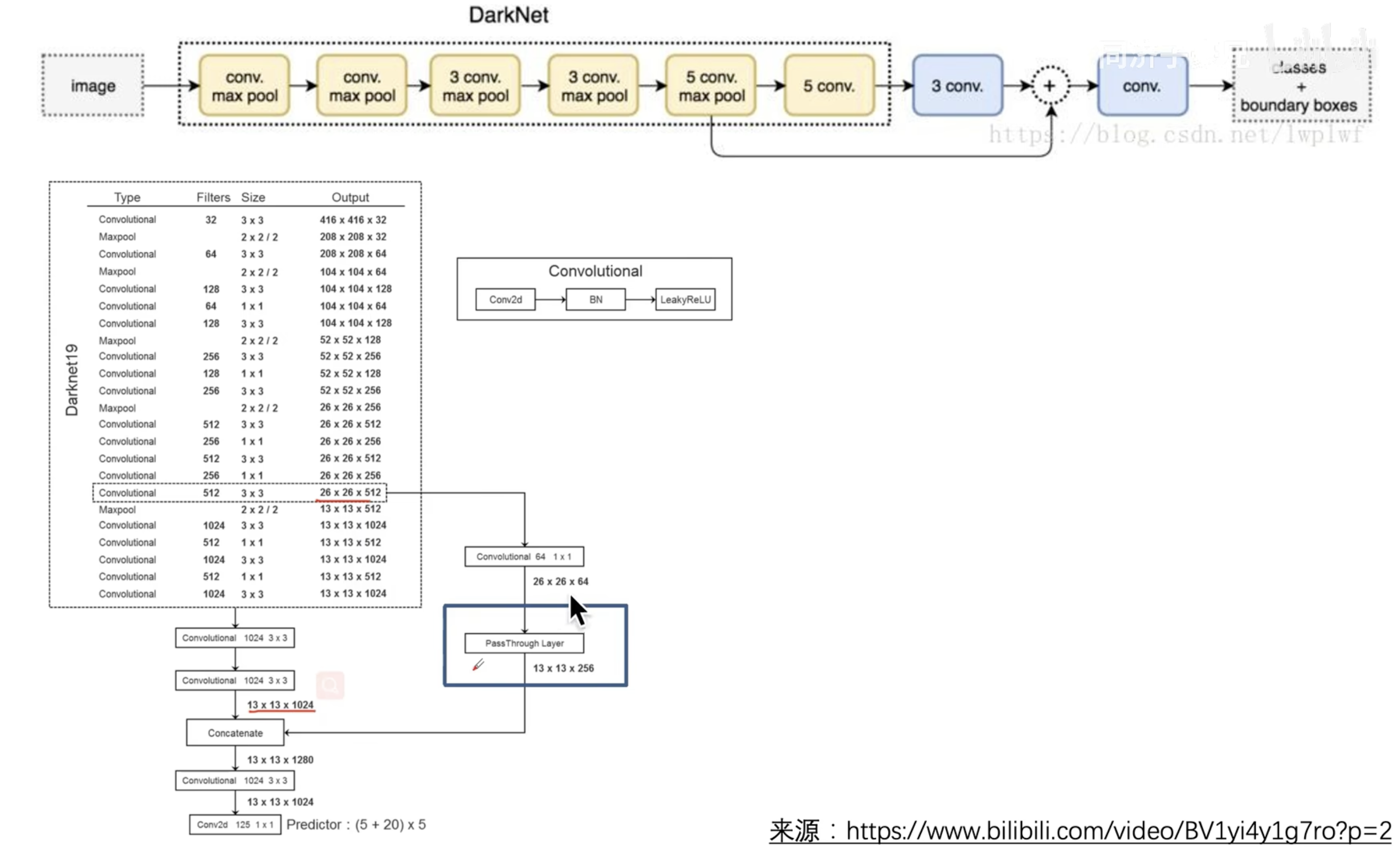
亿些细节
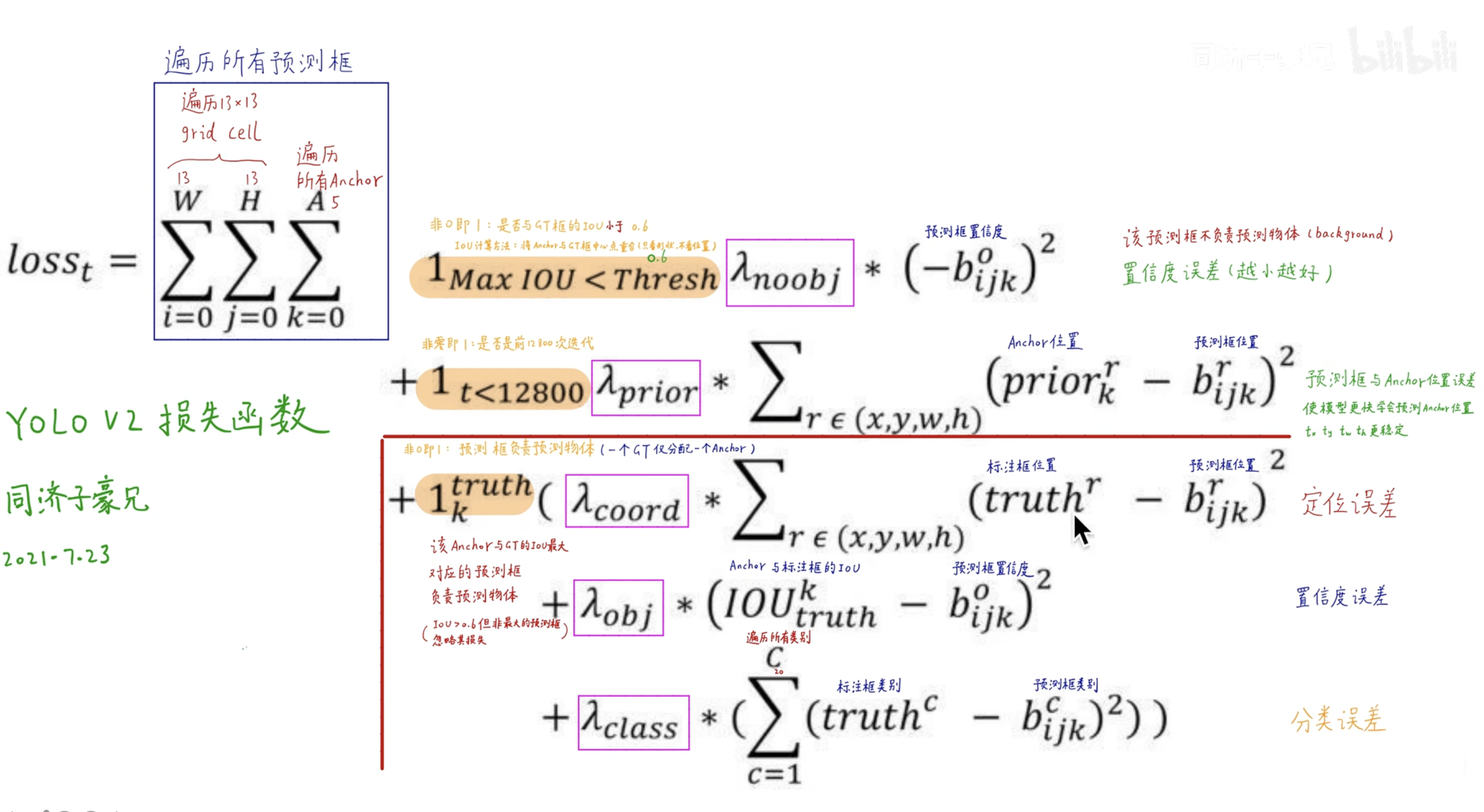
loss 设置
同样原 yolo v2 论文中并没有提供loss公式,这里同样参考 【精读AI论文】YOLO V2目标检测算法 中的公式
进一步了解
无
原文和代码
https://arxiv.org/abs/1612.08242