快速了解一个网络:YOLO, You Only Look Once (YOLOv1)
快速了解一个网络:YOLO, You Only Look Once (YOLOv1)
以下内容偏向于记录个人学习过程及思考,请审慎阅读。
背景
基于region proposals的二阶段目标检测网络太慢了
核心思想
提出一种一阶段的目标检测网络结构,将目标检测任务当作一种回归任务去做。
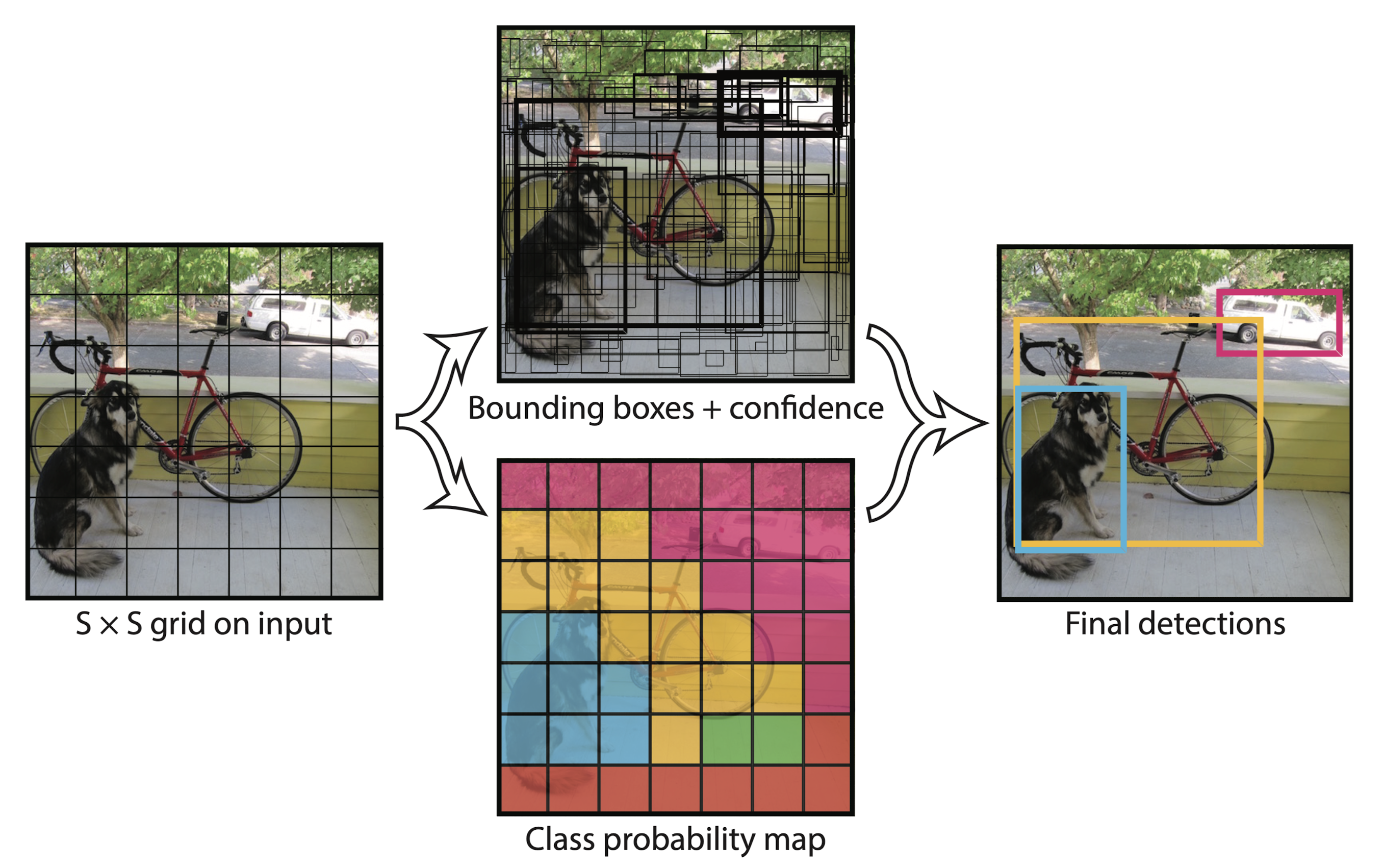
Pipeline
将输入图片分为 S x S 个 grid,每个 grid 预测 B 个框的位置和置信度 + C 个 class 的概率。
因此输出 encode 为 S x S x (B x 5 + C) 的 tensor
由于yolo是基于整张图像去做的(而非基于region proposals),所以yolo对于背景的识别错误率非常低。
但是yolo对于一群小物体的识别精度比较差。
亿些细节
Training
- bounding box的xyhw都经过了归一化,数值控制在0-1
- 由于大部分grid是不包含obj的,所以在设计loss时对于这些不含obj的grid对应的loss权重减少。
- 对于大框和小框都偏离相同的值,显然小框的偏离百分比会更大。若使用同样的平方和误差,对于大小框并不公平。因此这里考虑预测box的长和宽的平方根,以缓解这一问题。
- 训练阶段,对于每个物体仅唯一考虑一个IOU最大的预测器。loss只惩罚出现在对应grid cell的obj,同样也只惩罚IOU最大的预测的bounding box
- 作者使用了drop out, random scaling and translations, random exposure and saturation等防止过拟合
进一步了解
无
原文和代码
https://arxiv.org/abs/1506.02640
参考资料
无
本文由作者按照 CC BY 4.0 进行授权