快速了解一个网络:SSD, Single Shot MultiBox Detector
以下内容偏向于记录个人学习过程及思考,请审慎阅读。
背景
基于region proposals的二阶段目标检测网络太慢了
核心思想
提出一种一阶段的目标检测网络结构。基于规则,在不同层的不同位置产生不同形状的候选框,经过设计后这些候选框相对固定,规避了region proposals带来的时间。
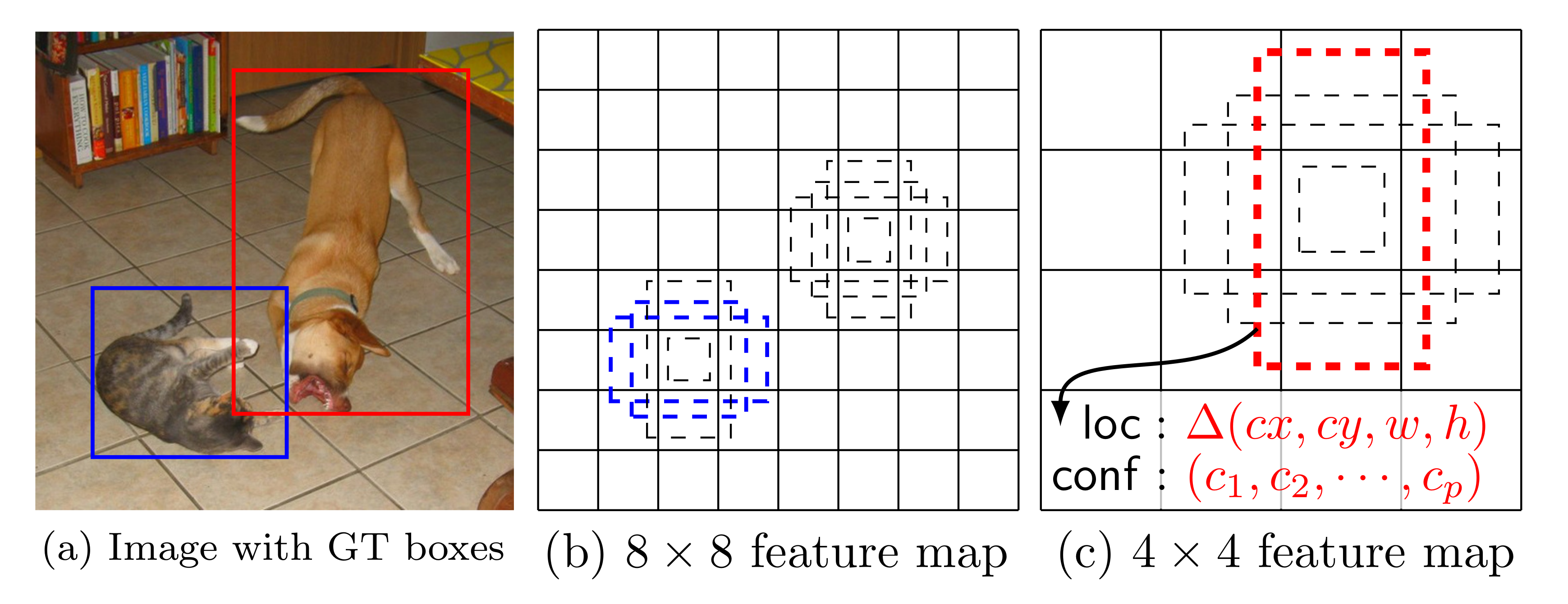
不同深度的卷积层,其感受野不同。
浅层的卷积层,感受野较小,此时的候选框面向的是小目标
较深的卷积层,感受野较大,此时的候选框面向的是大目标
因此,从不同的卷积层提取的这些候选框,保证了网络对于不同大小和尺度目标的检出能力。
Pipeline
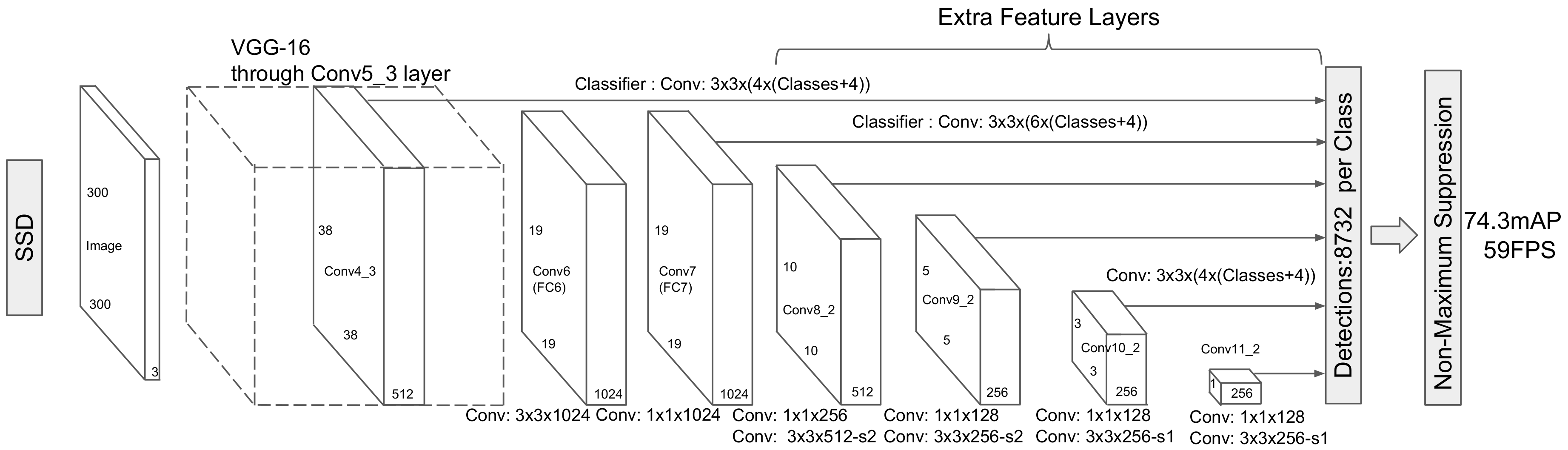
如图所示。作者将VGG-16的fc6和fc7层用卷积层进行了替代,并在后续也使用一系列卷积,将每层的feature map大小逐步减小(感受野逐层提高)。
对于 m x n 的feature map,每个位置会设置k个不同比例的候选框,每个候选框会输出c个类别的置信度及4个检测框相对于候选框的offset。因此每个 m x n 的feature map共有 (c+4)kmn 个输出。
亿些细节
Training
与MultiBox不同,只要候选框与GT的IOU大于0.5,就将其认为是正例。因此,SSD推理阶段会输出大量的目标检测框,需要作NMS来保留置信度最高的框。
假设我有m个feature map用于detection,如何针对不同层的feature map选择合适的scale呢?作者给出了一种线性的选择方式。设置好smin和smax后,即可推出中间层的s
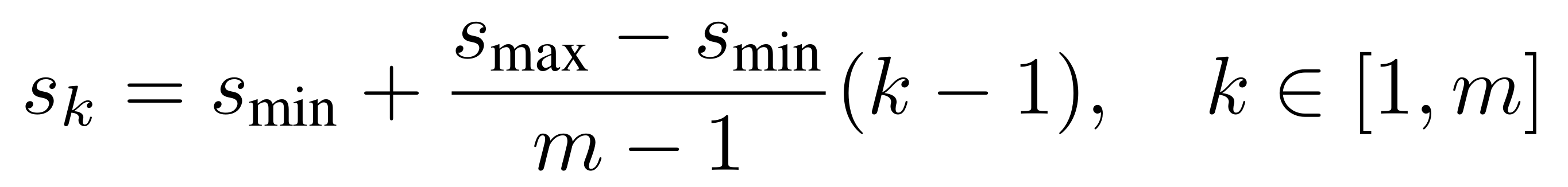
基于本文的思路,不包含待检测物体的候选框的数量会远远大于正例,对于训练来说会非常困难。作者这里是将loss最高的一些负例挑出来作反向传播,其余负例丢弃。作者认为负例:正例 = 3:1时,训练的效果比较稳定。
- 数据增强。这里作者考虑在以下3种策略中随机选取:
- 使用整张原始图像
- 按照和GT最小的IOU(0.1, 0.3, 0.5, 0.7, 0.9)随机截取一部分区域
- 随机截取一部分区域
- 对于小物体的检测精度提升,作者尝试将图片放置于基于平均方式的16倍上采样的图上,这样对小物体检测有一些提升。
进一步了解
无
原文和代码
https://arxiv.org/abs/1512.02325
参考资料
无