快速了解一个网络:SAF, Spatial Attention Fusion for Obstacle Detection Using MmWave Radar and Vision Sensor
快速了解一个网络:SAF, Spatial Attention Fusion for Obstacle Detection Using MmWave Radar and Vision Sensor
以下内容偏向于记录个人学习过程及思考,请审慎阅读。
背景
为了更好地融合radar & camera,提出一种新的融合策略
核心思想
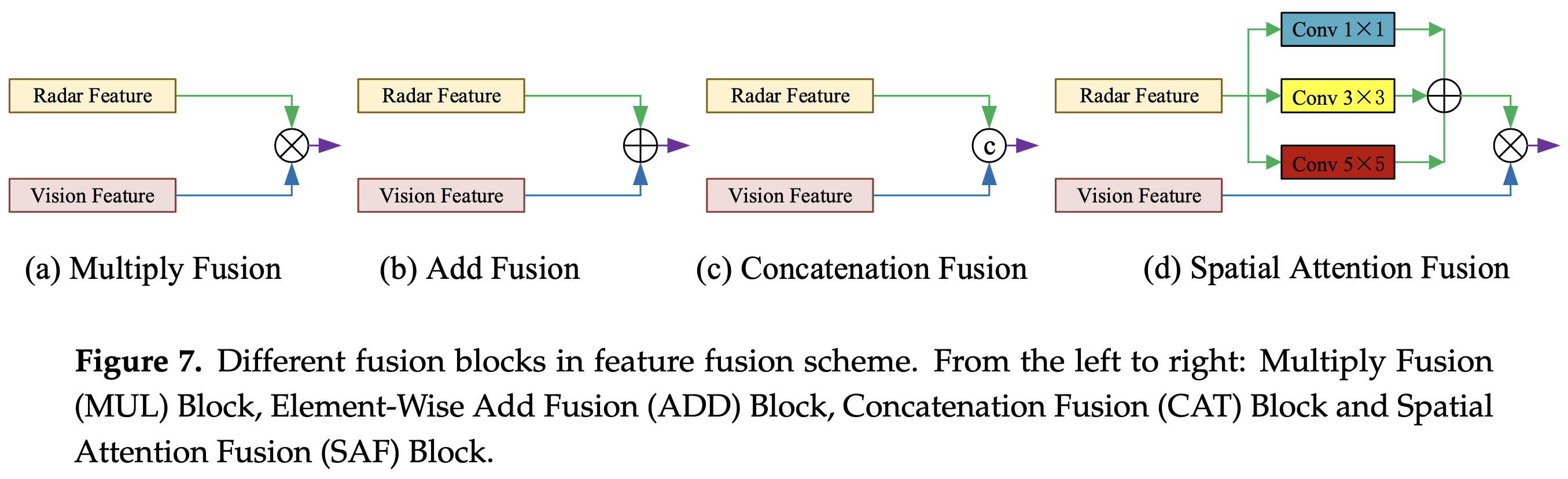
基于radar分支features,采用不同大小的卷积核(获得不同感受野)计算后求和,得到一个channel为1、HW与image features size一致的matrix,作者叫做”attention matrix”。
将”attention matrix”与image features相乘作为融合结果,再经过一系列卷积获得最终输出。
Pipeline
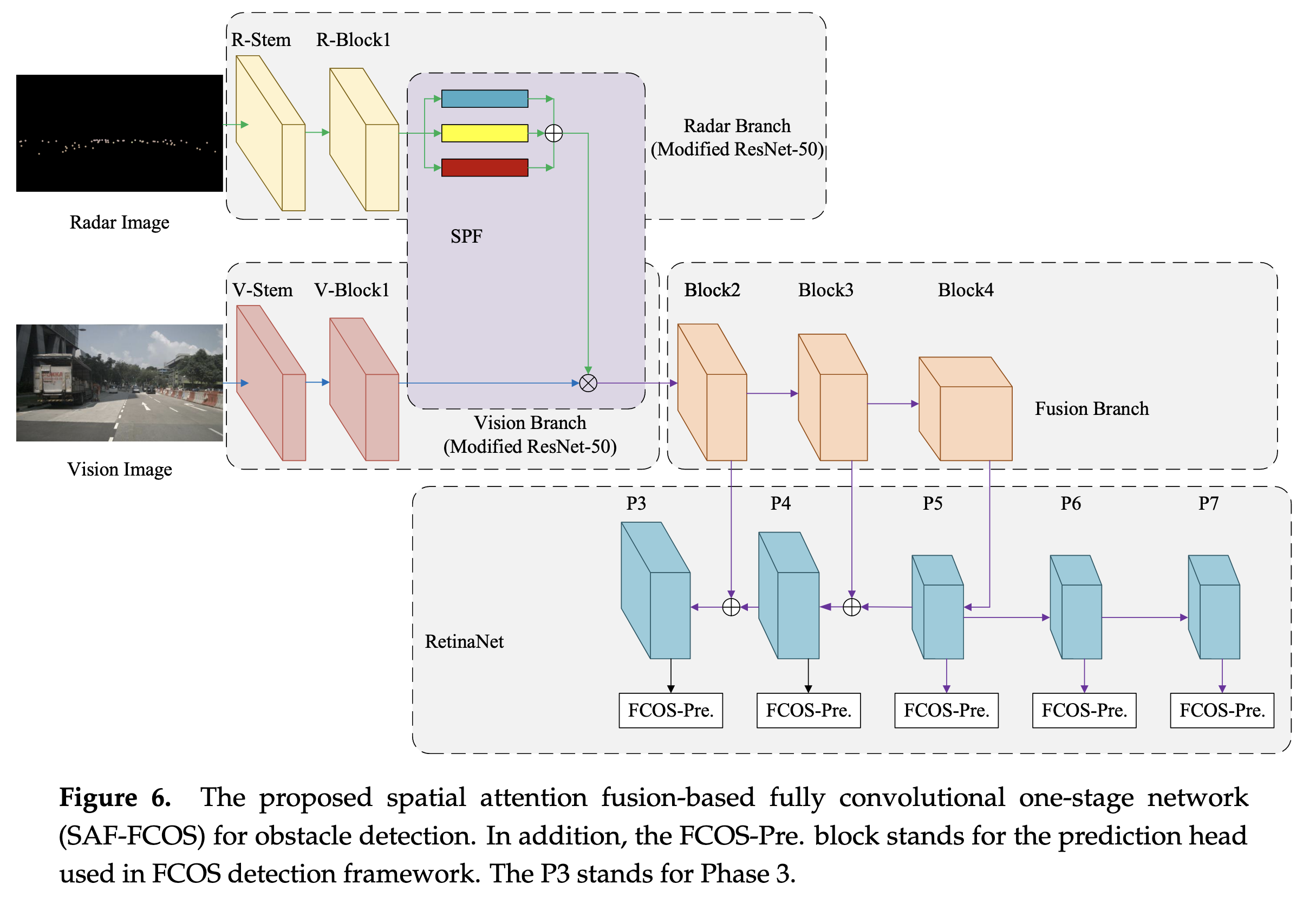
亿些细节
- 作者使用nuScenes数据集
- 时间对齐做的比较好,可以省略时间对齐相关工作
- 只使用前向camera和前向radar
- 对于radar点,只使用位置和速度信息
- nuScenes的数据标注是3d的,作者开始采用nuScenes的3d转2d工具,发现很多遮挡严重的框也会放出来(猜测应该是lidar位置更高可以看到更多信息的原因),作者认为这会让cnn网络的训练变的比较困难。于是自己用了一个比较大的fcos网络产生伪标注结果作为真值(个人感觉略牵强…
- 因为radar对于行人的检测效果较差,因此本文忽略行人相关检测。
- 类似于Distant Vehicle Detection Using Radar and Vision中的做法,作者同样是将radar点云通过内外参反投到camera图像上得到radar images。
- 这里作者给出来了详细的转换公式,表明了如何将radar的pos/vel_x/vel_y转换为0-255范围内(根据最大值设计好的归一化计算)
- 同之前的文章,这里考虑反投形成一个圈形区域而非单个像素。这里作者特别指出,如果圆形区域有交叠,那么选择将距离更近的点覆盖掉距离较远的点
- 作者解释了下为啥用R-Block1和V-Block1,而不是用3个残差块。
- 因为采用3个残差块时会出现nan,且多次重启训练仍会有。作者猜测是残差结构不适合稀疏的radar images(有没有可能是有bug…但佩服作者的老实
- 作者在attention过程中采用3种不同大小的卷积核,表明是希望融合获取不同的感受野。
- 作者同样提到几个未来的研究思路
- 考虑多camera & 多radar融合的思路,本文只考虑了前向的
- 多目标跟踪结果和多目标检测结果应该可以互相促进和帮助,可以考虑
进一步了解
原文和代码
https://www.mdpi.com/1424-8220/20/4/956
参考资料
无
p.s. 感觉这个attention matrix有点牵强,强行蹭热点的感觉啊。
作者甚至会建议你读一读源码(怎么感觉不像在写论文…

本文由作者按照 CC BY 4.0 进行授权