快速了解一个网络:RODNet, A Real-Time Radar Object Detection Network Cross-Supervised by Camera-Radar Fused Object 3D Localization
以下内容偏向于记录个人学习过程及思考,请审慎阅读。
背景
许多算法只考虑使用radar的点云信息,而忽略了原始radar signal中包含的丰富的语义、目标运动信息等。
这篇文章主要是基于radar的range-azimuth image来完成基于纯radar的目标检测,输出ego系下的目标检测中心点位置和类别(无size、朝向等)
真值方面依赖camera-radar fusion作为teacher网络来作cross-supervision,无需人工标注。
另外就是提供了一个带有range-azimuth image的数据集,CRUW dataset
核心思想
- teachar网络
- 基于camera分支实现基于单目的3d目标检测,再投影到radar系,与经过cfar检测的radar点云作关联和融合,最终得到目标的中心点位置和类别,当作真值来监督student网络
- student网络
- 基于radar signal的range-azimuth image通过cnn网络提取features,用teacher网络的输出结果来监督loss。最终经过nms后得到最终的目标位置和类别输出。
Pipeline
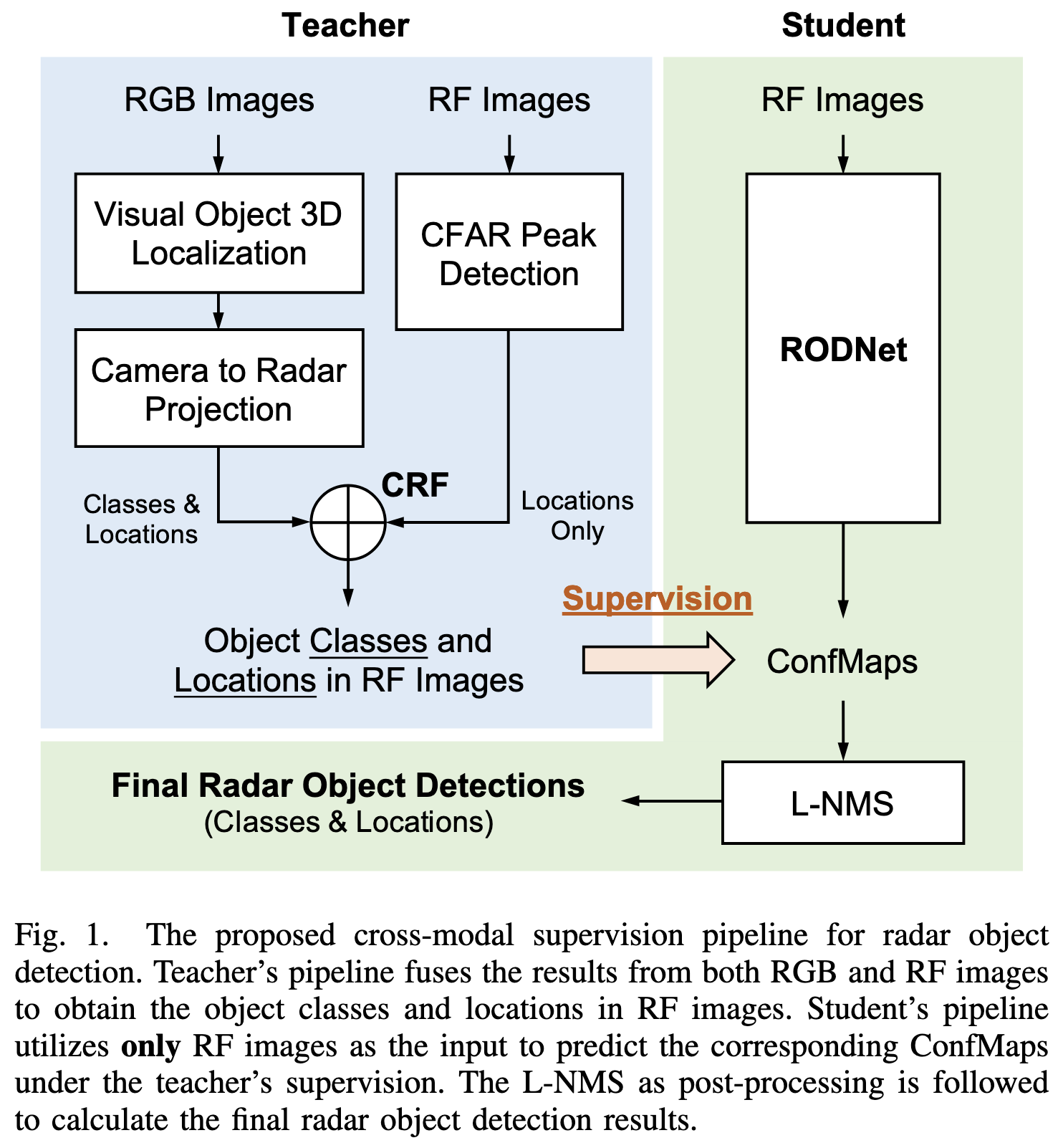
亿些细节
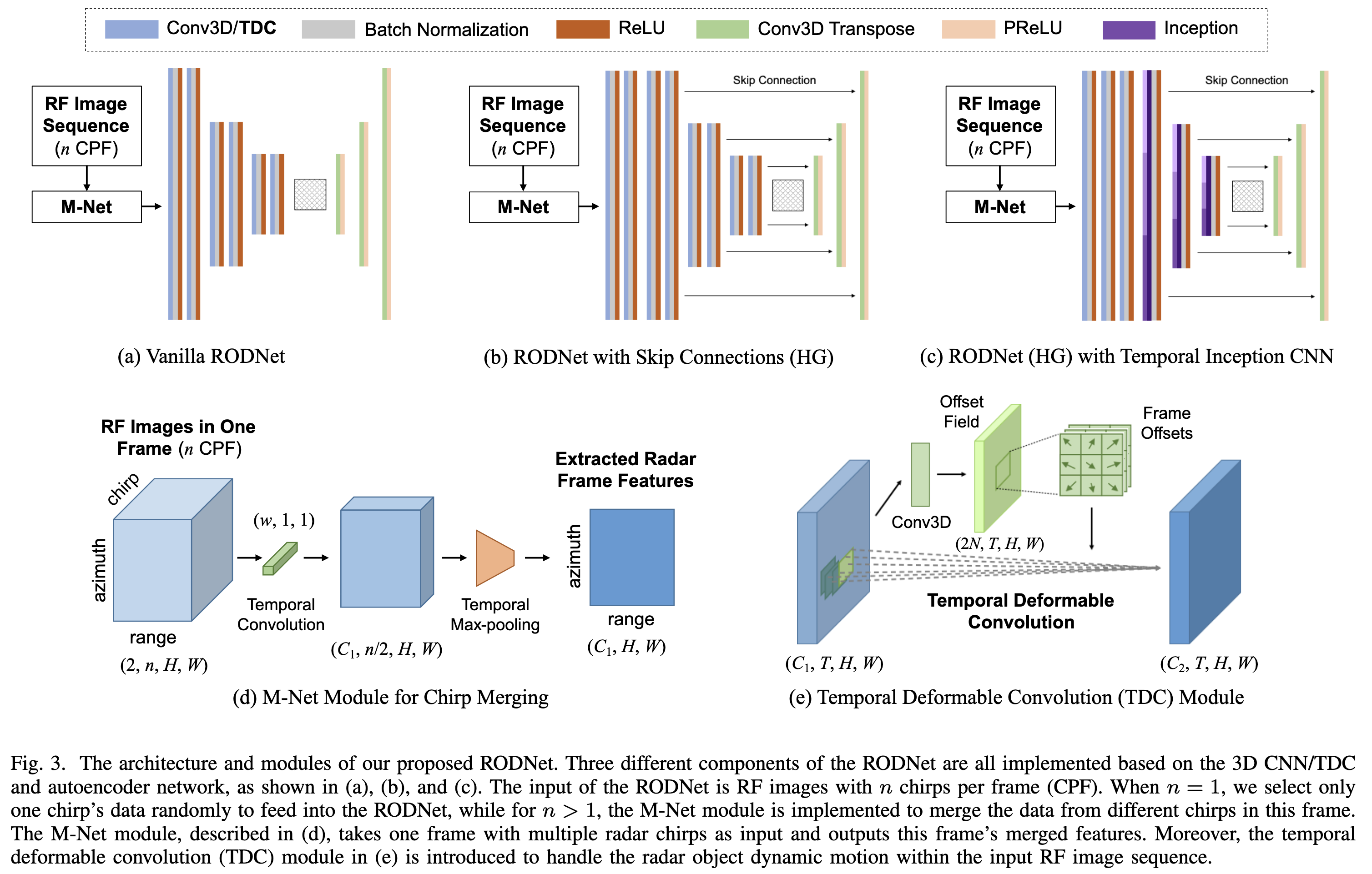
RODNet Architecture
基于一个3d cnn的autoencoder结构进行设计。因为radar的range-azimuth image是复数,因此这里作者将实部和虚部分别作为两个channel来处理。
M-Net Module
因为输入是n个chirp,这里作者考虑通过M-Net Module将时序上的chirp累积起来,包括卷积和max pooling(见上图)。
因此这个模块的作用类似于一个带Doppler补偿的FFT计算,只不过这里是通过网络学习的方式进行的。
每一帧都这样提取完features后,再沿着时序维concat起来当作RODNet的输入。
Temporal Deformable Convolution
因为目标的相对运动,radar位置可能在不同帧会有所偏移,而3d cnn无法很好的处理这种情况。
因此作者引入了类似Deformable Convolution Network的结构,在每个时序位置上额外学习一个空间上的偏移参数来进行Deformable Convolution。
Post-processing by Location-based NMS
类似于iou,作者提了一种基于位置的nms方法,通过计算目标的位置相似性(见原文公式)作为nms的标准。
将所有基于8-neighbor的峰值全部提取出来,存入一个set。
逐步取set中置信度最高的峰值加入结果,并遍历set中的其它峰值:如果set中另一个峰值点与该峰值点的位置相似度大于某个阈值,则删除另一个峰值点。
以此类推
Camera-Radar Fusion (CRF) Supervision
本质是基于一定规则分别将camera分支的输出和radar点云生成location heat map
二者的heat map均是基于Gaussian函数生成,方差基于传感器特性进行设置(详见原文公式)
二者features的融合的方式是element-wise product
进一步了解
- Monocular visual object 3d localization in road scenes
- DCN, Deformable Convolution Network
原文和代码
参考资料
无