快速了解一个网络:Low-level Sensor Fusion for 3D Vehicle Detection using Radar Range-Azimuth Heatmap and Monocular Image
快速了解一个网络:Low-level Sensor Fusion for 3D Vehicle Detection using Radar Range-Azimuth Heatmap and Monocular Image
以下内容偏向于记录个人学习过程及思考,请审慎阅读。
背景
在深度学习框架中利用低级雷达数据的3D对象检测尚未得到彻底研究。
核心思想
camera monocular image和radar range-azimuth heatmap各自经过image backbone和radar backbone提取features
基于3d anchors,投影到对应坐标系后分别从对应的feature map上取对应的features,经过卷积、concat后融合获得3d proposals
基于3d proposals,投影到对应坐标系后分别从对应的feature map上取对应的features,经过卷积、concat后融合获得最终的3d预测框
Pipeline
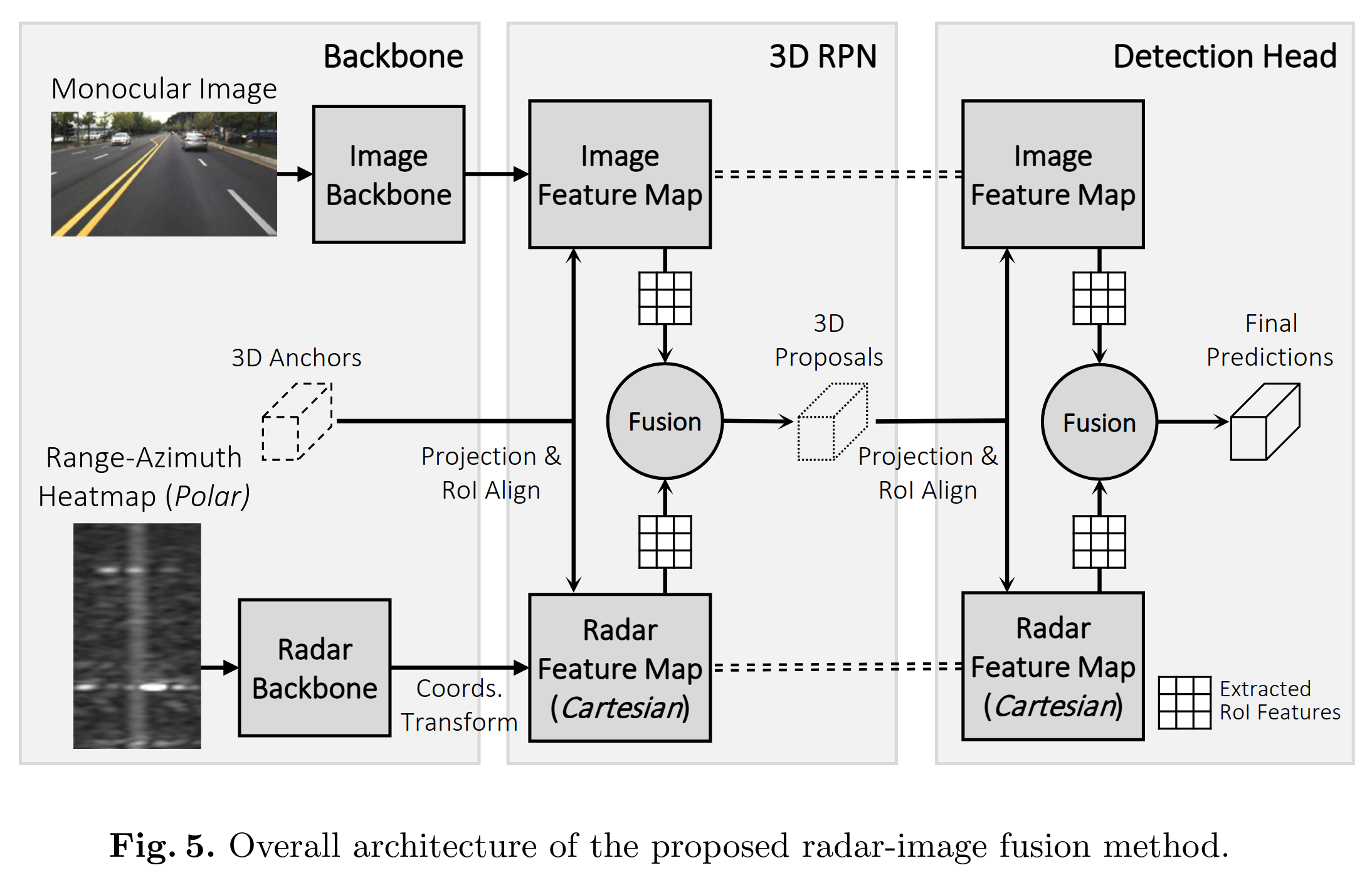
亿些细节
Data Acquisition and Annotation
ground truths label是通过lidar点云进行标注,再反投到radar坐标系得到的。
Radar Representation and Backbone
radar range-azimuth heatmap提取features后是在极坐标系,作者使用双线性插值将极坐标系转换到笛卡尔坐标系从而实现对齐
radar和image的backbone是由改造的VGG16 + FPN组成的。
3D Region Proposal Network
在将3d anchors投影到对应的feature map上时,使用了ROI align技术
作者强调减少离散量化带来的误差非常有必要,因为radar的角分辨率通常较低,1个像素的偏差也会导致较大的定位误差。
计算预测结果与GT的IOU时,作者发现较小的横向偏移会带来较大的IOU变化。
因此这里作者采用距离相关的metric来衡量计算预测结果与GT的差距。
进一步了解
- FPN
- ROI align
原文和代码
参考资料
无
本文由作者按照 CC BY 4.0 进行授权