快速了解一个网络:LoFTR, Detector-Free Local Feature Matching with Transformers
快速了解一个网络:LoFTR, Detector-Free Local Feature Matching with Transformers
以下内容偏向于记录个人学习过程及思考,请审慎阅读。
背景
现有的大部分特征匹配方法通常分为3步:
- 特征检测
- 特征描述
- 特征匹配
但是,在纹理条件不佳、图案重复、视角变化、照明变化、运动模糊等情况下特征检测器的效果将会受到比较大的影响,进而影响到后续的特征描述与特征匹配。
另外,基于CNN的系列方法感受野比较有限。人类做特征匹配时通常是兼顾了全局信息和局部信息。
因此作者认为感受野在特征提取的部分十分重要,而transformer类的方法在这个方面有比较大的优势。
核心思想
通过CNN + Transformer(self-attention + cross-attention)提取待匹配的两张图像的特征,再经过粗匹配、精匹配过程实现特征匹配。
Pipeline
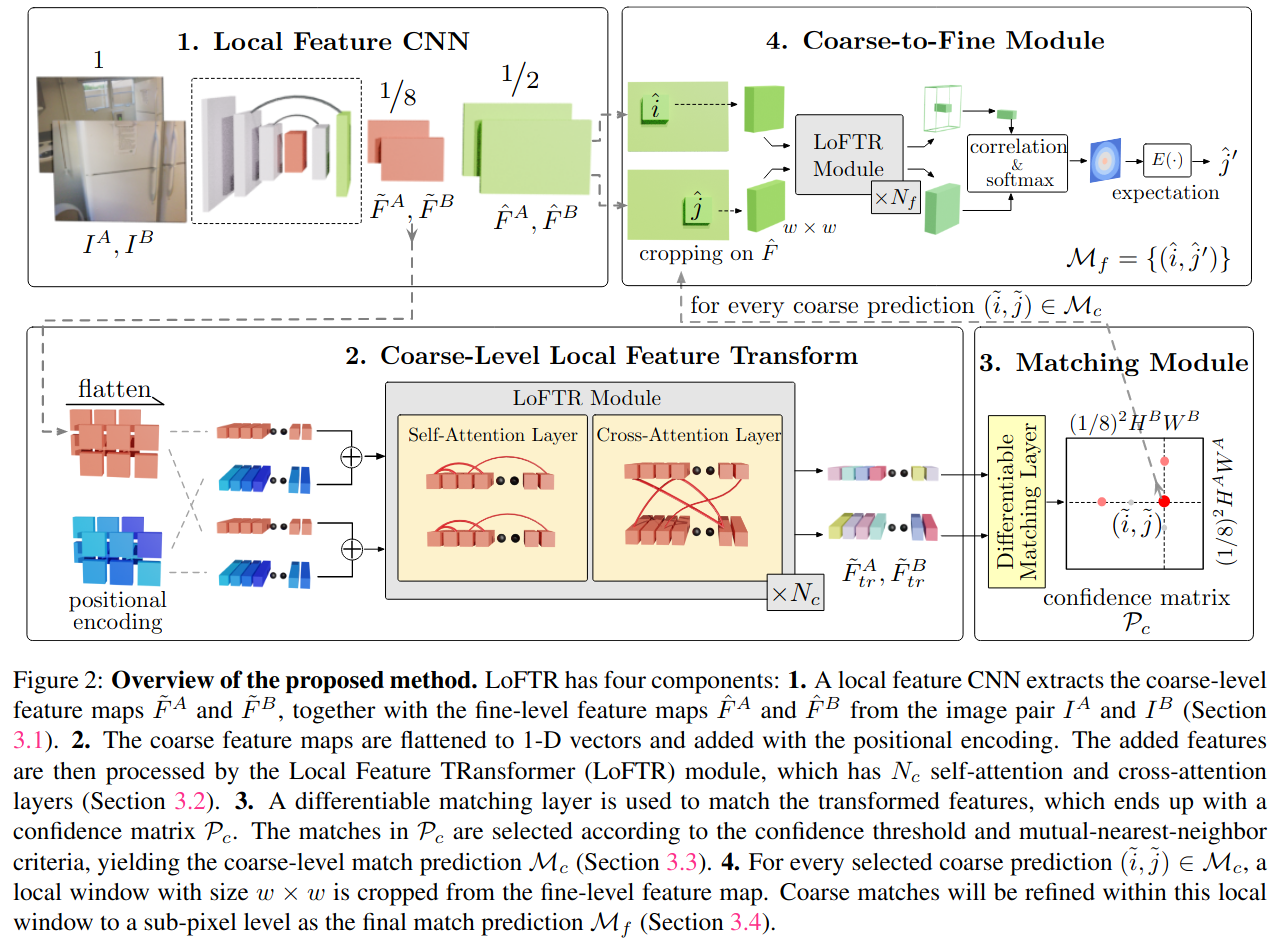
亿些细节
Local Feature Extraction
使用ResNet + FPN提取待匹配的两张图像的特征,分别保留1/8分辨率输出(用于transformer)和1/2分辨率输出(用于精匹配)
Local Feature Transformer (LoFTR) Module
使用Linear Transformer减小计算的复杂度至O(N)
Establishing Coarse-level Matches
可微的粗匹配层提供两种方法
- SuperGlue中的Optimal Transport Layer
- Dual-Softmax operator
匹配选择则采取mutual nearest neighbor (MNN)方式
Coarse-to-Fine Module
将粗匹配的点,映射到1/2分辨率特征上各提出wxw大小的local windows,进入一个小的LoFTR模块进行交互(self-attention + cross-attention)
将输出的两个特征做相关得到heatmap(概率分布),通过概率分布得到期望的精细匹配。
Supervision
粗匹配,使用在GT中的匹配点对应matching probability矩阵中概率,通过negative log-likelihood得到loss
精匹配,使用在GT中的匹配点,对应匹配下标的二次型 + heatmap的variance构造loss
进一步了解
- Linear Transformer
- SuperGlue
- Mutual Nearest Neighbor
原文和代码
https://arxiv.org/abs/2104.00680
参考资料
无
本文由作者按照 CC BY 4.0 进行授权