快速了解一个网络:GRIF Net, Gated Region of Interest Fusion Network for Robust 3D Object Detection from Radar Point Cloud and Monocular Image
以下内容偏向于记录个人学习过程及思考,请审慎阅读。
背景
作者认为lidar并不适合大规模量产车,原因是高价格、高维护性和低可靠性。
radar和camera的组合才是比较适合商业量产车的组合,两个传感器特性可以让其优劣势互补。
为了更好的融合radar和camera,从更低level的feature融合出发是更有必要的。
核心思想
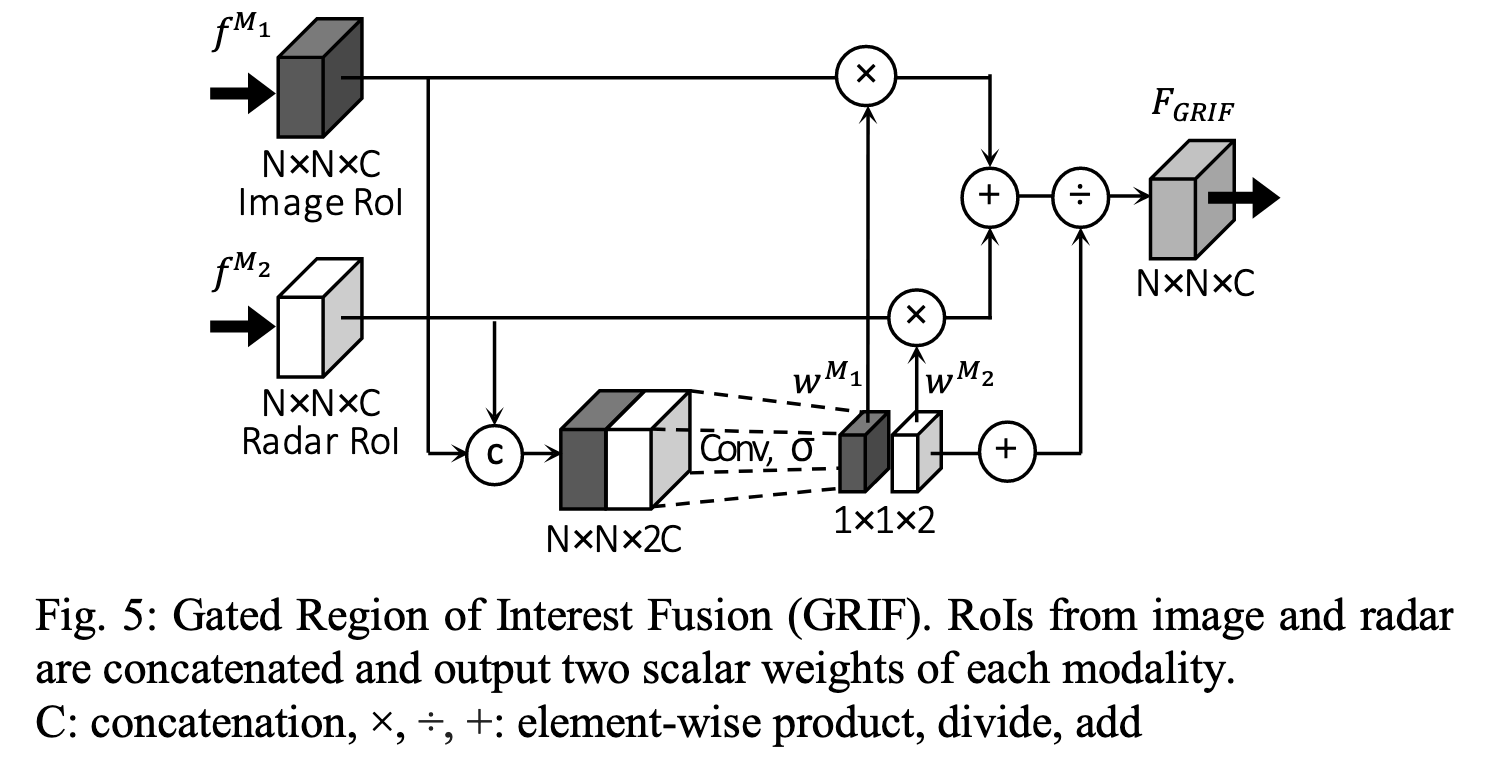
不像常规的cancatenation或者element-wise相加/求平均的融合方式,作者使用了gated region of interest fusion (GRIF)的方法
GRIF将radar和image对应roi区域的features concate起来,通过卷积生成2个权重。
基于这2个权重对相关roi区域的radar features和image features进行加权求和来进行融合。
思想类似于SeNet中的attention思路,让网络自适应的学会调整不同roi区域中两个不同features的权重。
Pipeline
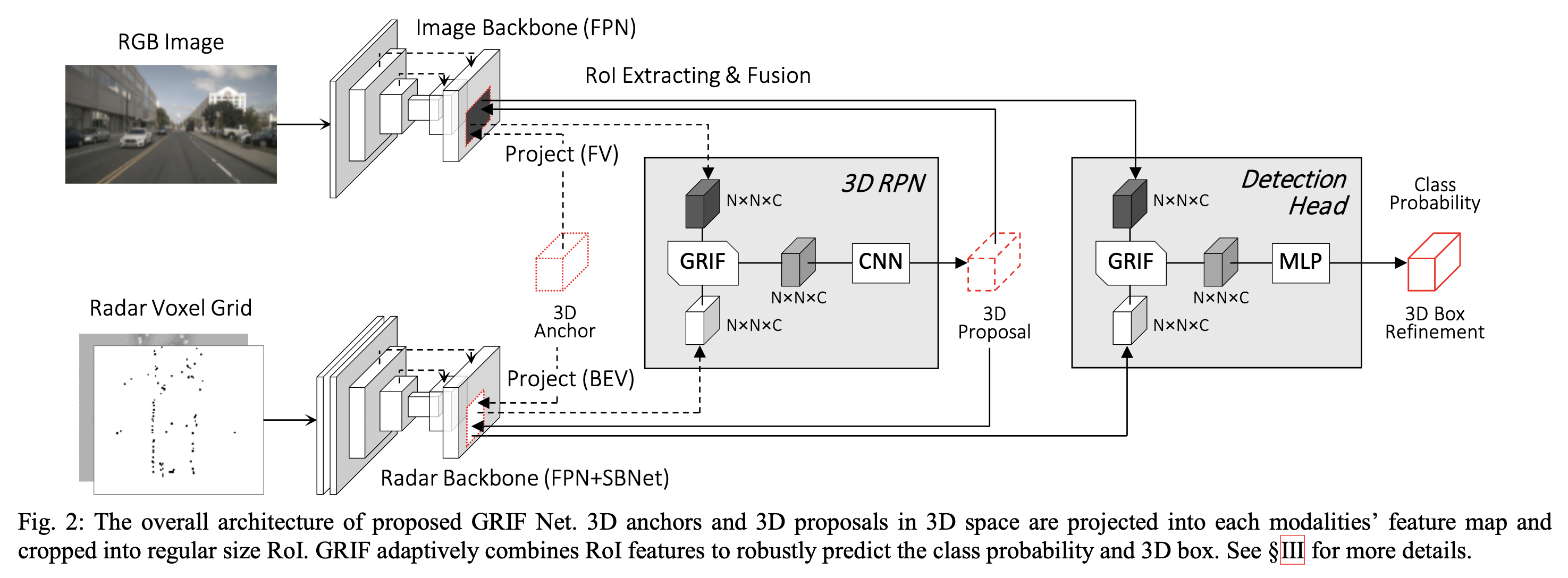
亿些细节
Radar Point Cloud Representation
因为单帧radar点云比较稀疏。作者通过积累6帧、大概0.5s的radar观测来使得点云变的稠密一些。
- 自车运动带来的radar点云位置变动,作者通过自车运动信息进行补偿
- 他车运动带来的radar点云位置变动,作者通过radar点云自身的Doppler信息和位置信息进行运动补偿
随后作者基于bev累计的radar点云voxelize到一个3 channel、分辨率为0.2m的grid map上
3个channel分别对应radar绝对速度、rcs信息以及occupancy信息。
如果一个voxel里有radar点云,那么occupancy为1,反之为0
如果一个voxel里有多个radar点云,那么对所有点云取最大值。
Multi-layer 3D Anchor
参考RPN的做法,作者会预先生成一些3d anchors,分别反投到radar的bev和image的fv,形成一些ROI proposals
根据对训练集作size的k-means聚类,共将3d anchor size分成了两大类
3d anchors在bev x-y平面以0.5m间隔进行生成,包含0和90两个角度,并且在z方向上以1m的间距进行堆叠
Image Backbone Network
image backbone采用fpn
Radar Backbone Network
采用fpn + Sparse Block Network (SBNet)
SBNet的好处是可以仅在mask的区域进行卷积,优化因radar点云稀疏性带来的计算效率的降低。
考虑到感受野以及radar点云的位置误差,以每个radar点云为中心的1m的圆形范围叠加作为mask
这些mask大概会占到整个voxel map的26%
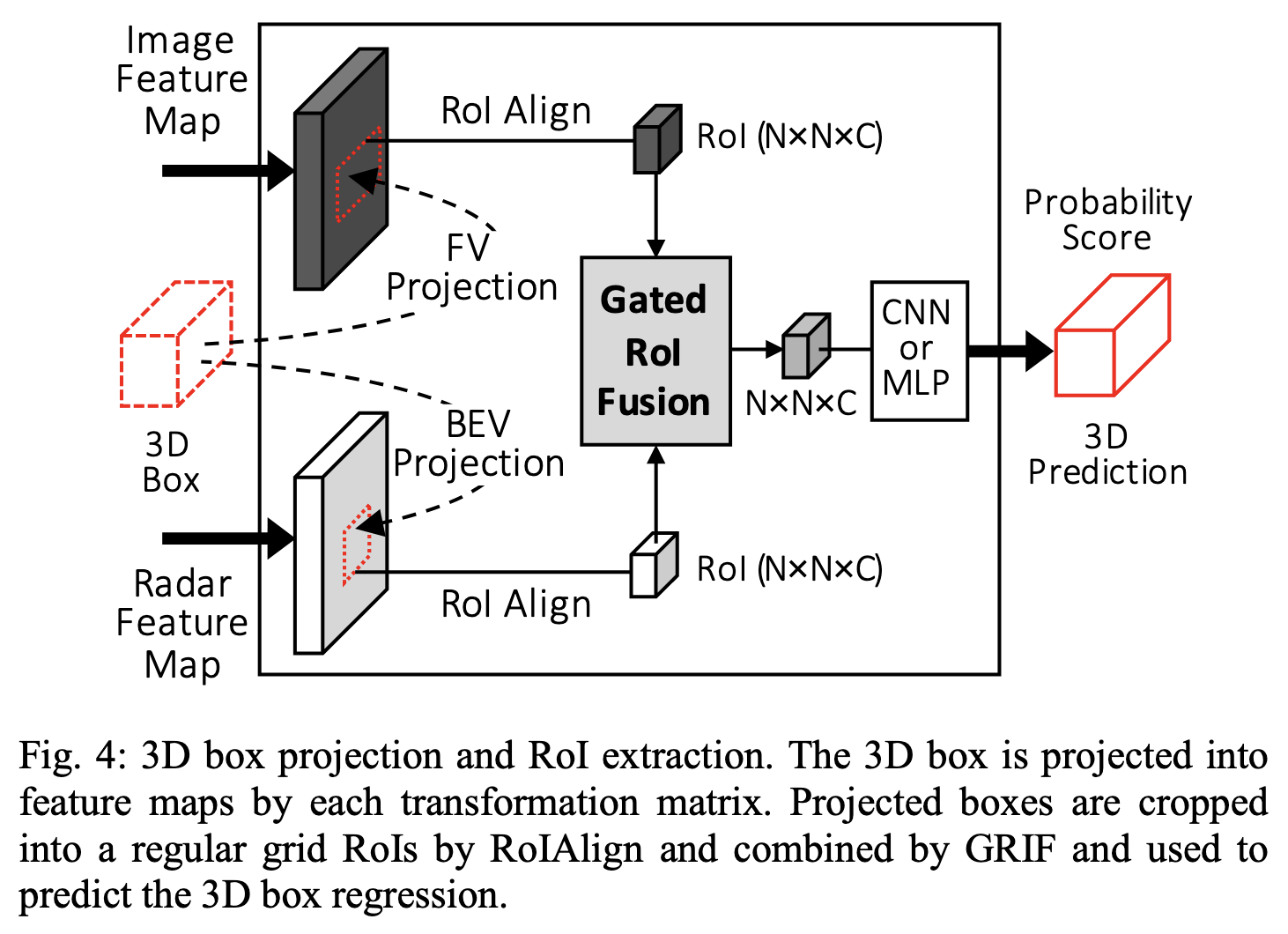
Gated Region of Interest Fusion (GRIF)
如上图所示,作者通过训练网络自适应的对roi区域的radar features和image features进行加权求和来进行融合。
并且作者并没有将两个features反投到同一个view上,而是一个bev、一个fv,但roi区域是对应上的。
convolutional Mixture of Experts (MoE)
Experiments
基于nuScenes数据集,使用1个前相机和3个前radar。
过滤掉了50m外不包含lidar点云和radar点云的车。
作者基于这套网络结构尝试了单独radar的方式,发现recall较低。作者解释是很多目标没有radar点且单独的radar观测缺少纹理信息。
而radar-camera融合的方式可以逼近lidar-based PointPillars的效果(3.1%的AP差距)
同时作者认为radar安装在车辆较低的位置,对一些遮挡车辆的检测可能会受到影响。
消融实验显示
- 在z-axis多层anchor的堆叠是有必要的
- ROI size 的设置对检测效果影响很大
进一步了解
- FPN
- Sparse Block Network (SBNet)
原文和代码
https://ieeexplore.ieee.org/document/9341177/
参考资料
无