快速了解一个网络:FusionNet, Radar and Camera Early Fusion for Vehicle Detection in Advanced Driver Assistance Systems
快速了解一个网络:FusionNet, Radar and Camera Early Fusion for Vehicle Detection in Advanced Driver Assistance Systems
以下内容偏向于记录个人学习过程及思考,请审慎阅读。
背景
为了提升自动驾驶系统在多种工况下的鲁棒性,作者考虑了一种radar camera前(早)融合的方案。
通常认为,对于不同传感器,features更早的融合可以获得更好的检测准度。
核心思想
将camera features和radar features(基于range-azimuth image)在空间维度对齐后(对于camera作IPM变换,对于radar作Polar to Cartesian变换),再借鉴SSD的思想,在不同level上对radar和camera features进行融合,融合方式采用concatenation
Pipeline
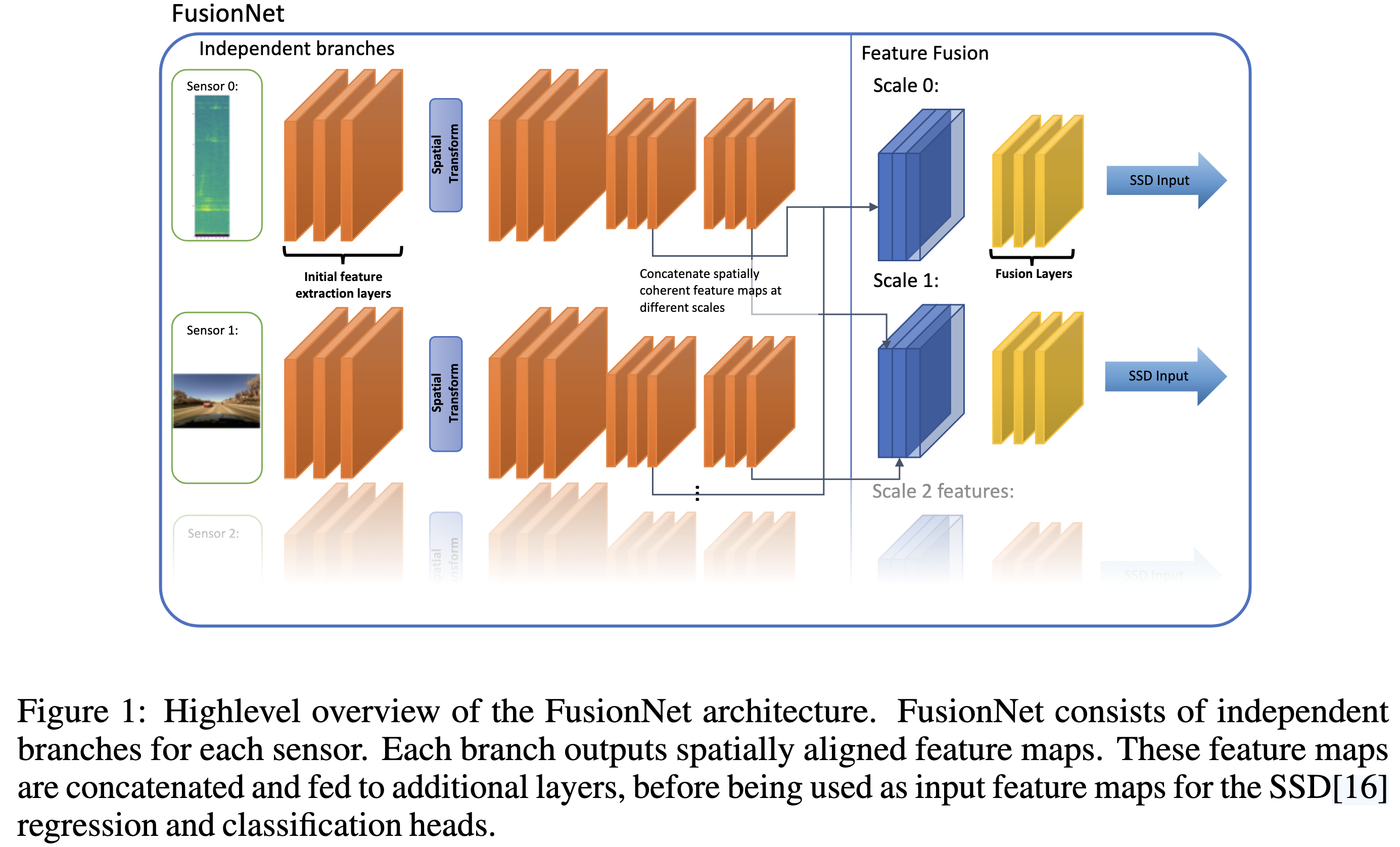

亿些细节
- camera和radar会使用两个分支提取features,并会通过空间变换将二者进行空间对齐(地面水平假设)
- 对于radar,是将range-azimuth image,进行Polar to Cartesian变换
- 对于camera,是将image通过IPM (Inverse Projective Mapping)算法,变换到Cartesian坐标系

- camera和radar提取features空间对齐后,通过concatenation进行融合得到二倍channel的输出。使用p=0.5的dropout分别从两个分支提取部份features,再通过1x1卷积将channel减一半。
- 目标检测方面,作者采用的是SSD检测头
- 数据方面,作者声明没有公开数据集有radar的range-azimuth数据,因此是作者自己采集的数据。对于radar data仅做3d-fft得到range-azimuth-doppler image,没有进一步做cfar检测得到radar点云。采用lidar大模型输出结果作为真值进行监督。
- 通过实验,作者发现camera分支可以得到更好的位置和尺寸估计,而radar分支可以提高mAP。特别是对于位置方面,二者融合的输出效果比radar分支的输出效果是更好的,因此二者融合后效果提升的目的就达到了。
- 训练实验中,作者发现先训练好camera分支然后冻住权重再联合训练radar分支可以获得最好的效果。
- 作者尝试解释是camera分支的features比较丰富且复杂,训练速度远不及radar分支。如果一起训练容易让网络偷懒,过于依赖radar分支
- 关于消融实验,作者是通过对于某一个分支添加噪声或者置零某个分支的输出实现的。
- 作者发现当去掉radar分支时mAP的掉点比去掉camera分支时mAP的掉点要严重
进一步了解
- SSD
- IPM, Inverse Projective Mapping
原文和代码
Radar and Camera Early Fusion for Vehicle Detection in Advanced Driver Assistance Systems
参考资料
无
本文由作者按照 CC BY 4.0 进行授权