快速了解一个网络:FPN, Feature Pyramid Network
以下内容偏向于记录个人学习过程及思考,请审慎阅读。
背景
基本上本文的idea可以用两张图说清楚,第一张如下。
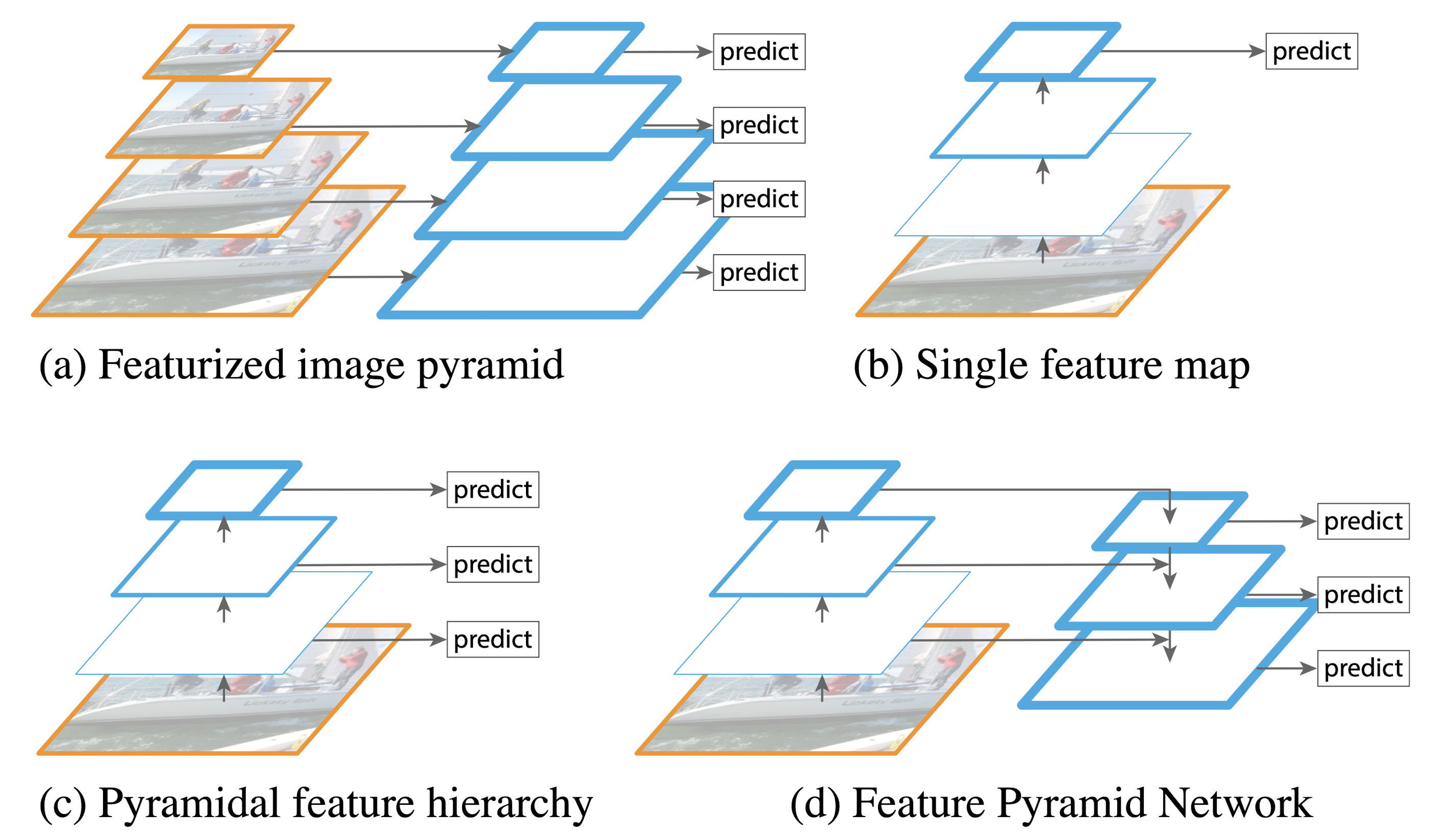
图(a) 表示图像作降采样形成图像金字塔,在不同层提取feature可以对各种尺度的目标都有比较好的检测效果,但缺点也显而易见,就是耗时 + 耗内存
图(b) 表示了RCNN系列算法,即通过CNN网络,叠加多层卷积,来获得最后的feature map。从最后含有丰富语义信息的feature map作分类或检测也比较天然。但这种做法的问题就是,虽然层数越深语义信息越丰富&网络对图像的理解越好,但随着卷积层数的不断加深,网络对图像的局部和细节也会丢失更多。这就有一种“细节特征”和“全局语义”不可兼得的感觉,随着网络层数加深,此消彼长。
图(c) 表示了以上问题的一种改进思路,即对每一层卷积层的feature map上都去作预测,这样我就可以在不同的“细节特征”和“全局语义”程度下作出预测,也许就可以获得更好的结果。但这样做的提升效果也并不显著。
图(d) 则表明了本文的思路,即“细节特征”和“全局语义”的融合。
核心思想
如上所述,FPN是想做“细节特征”和“全局语义”的融合。
这种结构可以嵌入到很多现有的网络架构中,并且可以无痛涨点!
Pipeline
如图(d)所示,本文对于不同卷积层提取的feature map,通过1x1卷积(统一channel数) + 临近插值升采样(统一feature map大小)的方式,将不同卷积层的输出统一并求和,进而获得不同层的“细节特征”和“全局语义”的一种融合。如下图所示
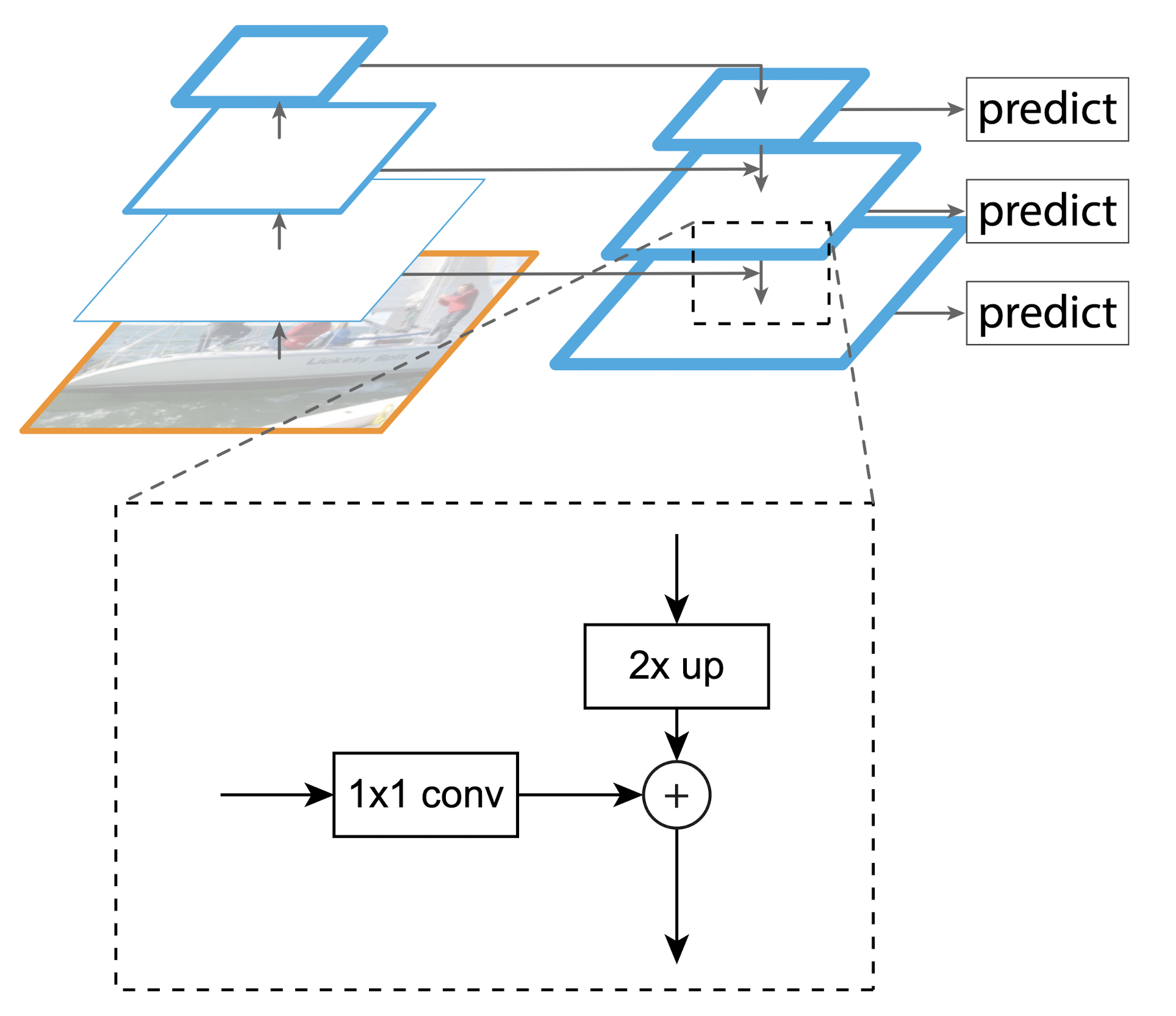
从FPN结构详解 视频里捞到一张up主自己画的图,会更详细一点
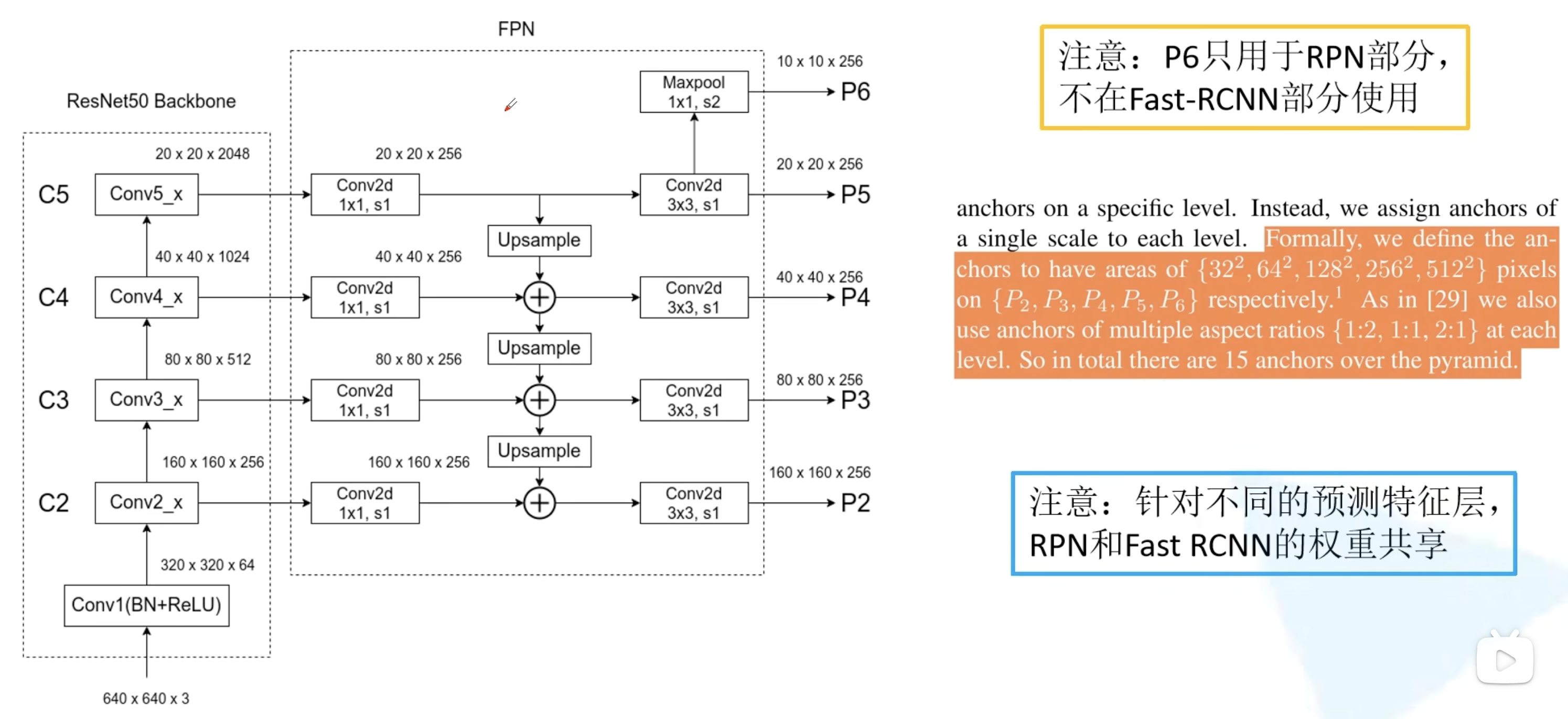
亿些细节
heads是否共享参数
对于每一层的融合预测,后续接的head是否需要共享参数?
作者对比实验表明共享和不共享二者差求不多。
作者认为这也说明了,FPN中的每一层都使用了相似的语义特征。
进一步了解
无
原文和代码
https://arxiv.org/abs/1612.03144