快速了解一个网络:DETR, End-to-End Object Detection with Transformers
快速了解一个网络:DETR, End-to-End Object Detection with Transformers
以下内容偏向于记录个人学习过程及思考,请审慎阅读。
背景
现有目标检测器通常是通过“边界框”回归和“分类”预测两个任务组合完成,且需要后处理操作(NMS)进行重复框的去除。
核心思想
本文将目标检测任务看作“直接集合预测”任务,通过二分图匹配的算法进行预测框和GT框的关联,基于transformer的encoder-decoder架构进行任务学习。
Pipeline
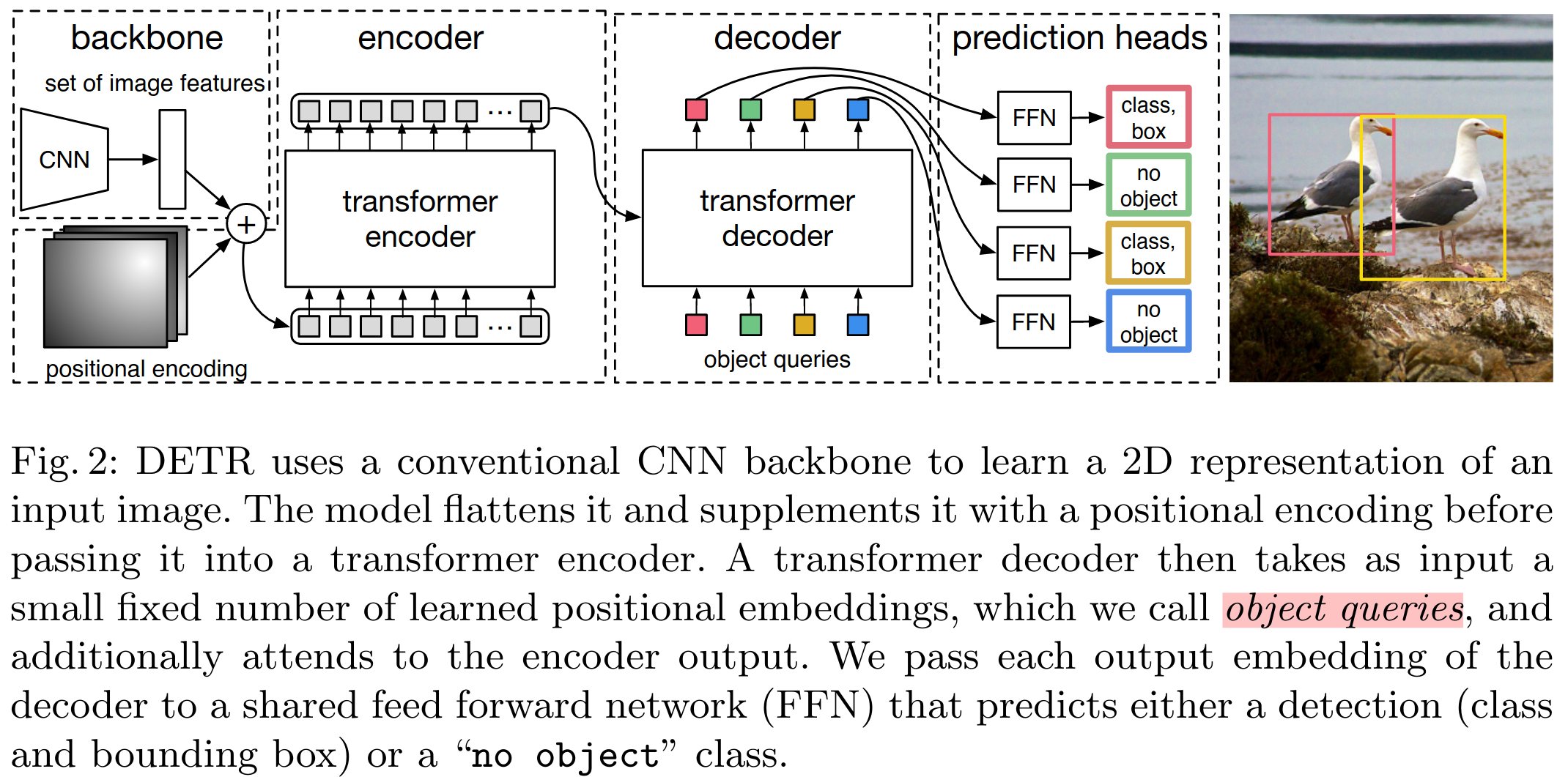
其中,N个object queries是网络可学习的参数。
亿些细节
- DETR是在decoder中直接并行解码预测N个框的位置和类别,N明显大于图中的目标数量,多出的部分填为“no object”
- Bounding box loss,作者采用L1 loss + generalized IoU loss的方式
- ablation实验显示FFN对于结果影响比较重要,且所有N个目标的FFN共用参数
进一步了解
原文和代码
https://arxiv.org/abs/2005.12872
https://github.com/facebookresearch/detr
参考资料
无
本文由作者按照 CC BY 4.0 进行授权