快速了解一个网络:Deformable DETR, Deformable Transformers for End-to-End Object Detection
快速了解一个网络:Deformable DETR, Deformable Transformers for End-to-End Object Detection
以下内容偏向于记录个人学习过程及思考,请审慎阅读。
背景
- DETR的训练收敛较慢,需要较长时间的训练才能收敛。
- 一方面,最初注意力权重是全局平均分布的,对于最终学到稀疏的注意力权重需要较长时间的迭代
- 另一方面,高算法复杂度也是需要长时间迭代的一个原因
- DETR未引入多尺度特征,因此在小目标检测方面效果不佳;未引入的原因之一是DETR的复杂度和输入feature map的大小平方成正比,复杂度过高
在CNN领域,deformable convolution是一种强大而有效的机制可以用来处理稀疏的空间位置。而DETR的优势则在于元素与元素间的交互和关系建模。
核心思想
作者考虑结合deformable convolution的稀疏空间采样和Transformers强大的关系建模能力,提出Deformable DETR。
Pipeline
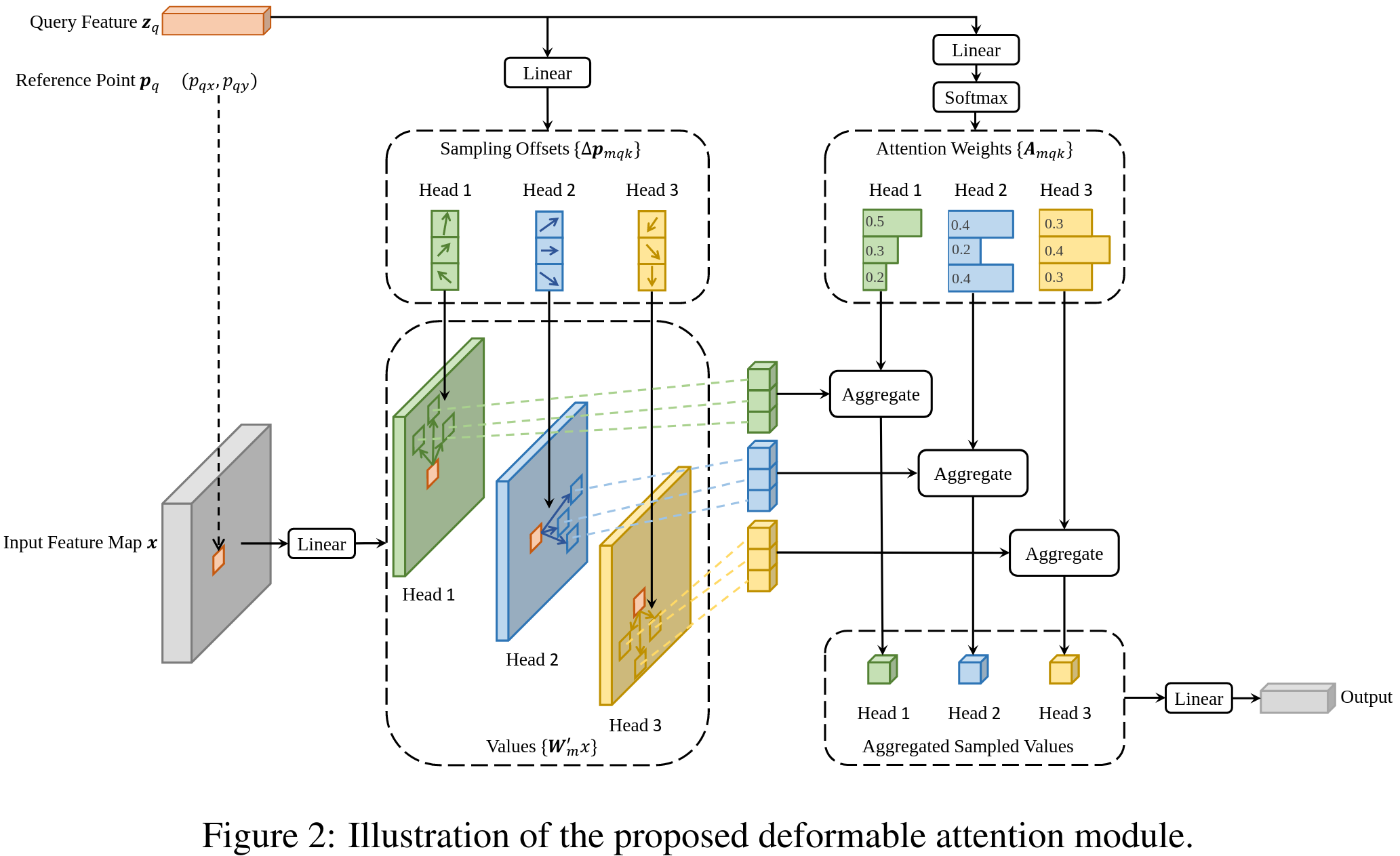
亿些细节
- deformable attention模块只使用参考点(reference point)附近的几个采样点的features,而非遍历整个features map,因此计算量大大减小
- 偏移量是通过参考点query feature线性映射得到的,因此是小数。这里作者利用了bilinear进行插值
- 每个参考点对应的features zq(沿channel维展开的向量),通过线性映射为3MK个channels,其中2MK个channels用于编码M个head、K个偏移点的x, y偏移量;MK个channels用于编码对应的attention weights
- 为解决Multi-scale Features大小不一的问题,这里参考点坐标使用对应层level的输入features map大小作了归一化
- 作者没有加FPN,作者认为其提出的Multi-scale Deformable Attention Module起到了FPN的作用,且后续实验表明增加FPN对结果影响不大
- 为了区分每个参考点来自、哪层level的features,作者新增了scale-level embedding(并非固定,随机初始化并在后续训练中更新)
- 在Deformable Transformer Decoder中,对于每个object query,对应的2d ref point是通过其object query embedding过一个线性映射+sigmoid学的,且会作为2d box center的初始guess
进一步了解
原文和代码
https://arxiv.org/abs/2010.04159
https://github.com/fundamentalvision/Deformable-DETR
参考资料
本文由作者按照 CC BY 4.0 进行授权