快速了解一个网络:CRF Net, A Deep Learning-based Radar and Camera Sensor Fusion Architecture for Object Detection
快速了解一个网络:CRF Net, A Deep Learning-based Radar and Camera Sensor Fusion Architecture for Object Detection
以下内容偏向于记录个人学习过程及思考,请审慎阅读。
背景
camera的图像质量在极端天气或低光黑暗场景极为受限。
camera的原始图像包含的是细粒度的像素点RGB信息,而radar则包含目标距离、速度等更高阶的信息。
而concatenation的融合方式隐含着两者的语义信息/level应该相近。
因此提出一种radar-camera融合框架,自动学习二者在什么level下进行融合可以获得更好的检测效果。
核心思想
在对image逐层卷积的过程中,也将radar的信息逐层concat进去,让网络通过更新权重能够自动学习哪层的concatenation可以获得更好的检测效果。
radar信息则是通过maxpooling进行逐层降采样,以保持和image的分辨率一致。
在训练过程中,以一定概率随机将camera所有相关神经元全部失活,让网络可以尽可能多依赖radar信息进行训练,作者称作BlackIn
Pipeline
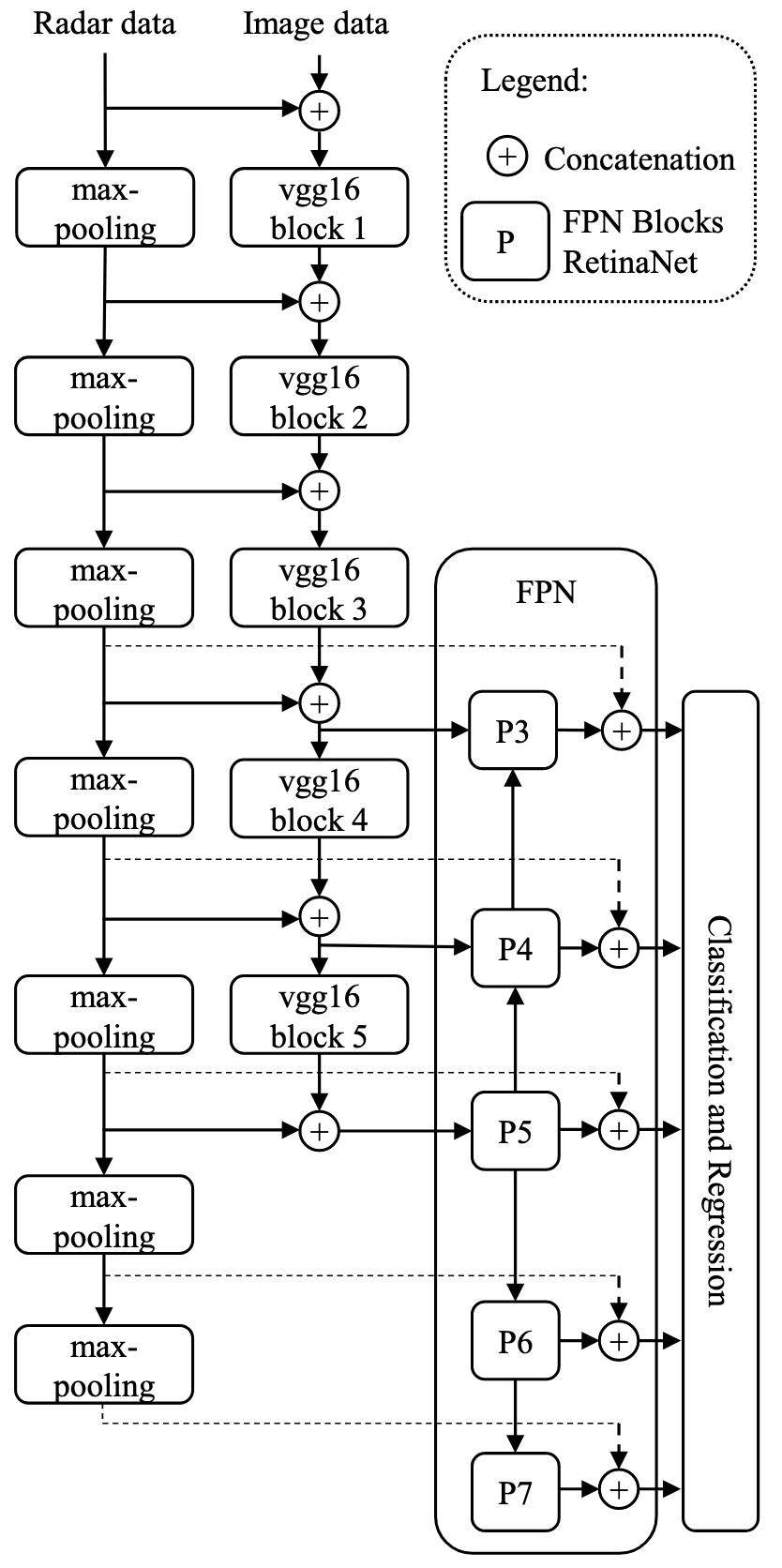
亿些细节
- 作者同样是将radar点云通过内外参反投到camera图像上,通过concatenation的方式进行融合。
- 因为radar点云没有高度信息,这里作者默认radar点云高度是地面高度,反投到图像后再竖直向上延伸3m得到“线段云”,线段宽1个pixel,作为radar image

- 为了改善radar点云的稀疏特性,作者将过去约1s内的radar点云通过自车运动补偿后全部反投到当前图像。
- 由于其它运动目标无法进行精确的运动补偿,这个操作也会引入很多radar noise
- 因此作者采用了一个annotation filter,只保留3d box内的radar点云。注意,这个操作在实际中是不可用的(实际中并没有3d box gt),作者说明这里仅仅是为了展示在radar noise较少时radar-camera融合后的效果。后续将进一步研究不依赖groud truth的radar点云预处理技术以减少噪声(饼)。
- 即使采用了过滤器,这样做产生的radar data也不是完美的,一些正确的radar观测也有可能被过滤掉,原因有4个
- 未补偿运动目标,过去的radar点有可能反投不到当前图像对应的目标3d box内
- 轻微的radar、camera标定误差导致
- 轻微的radar、camera时间对齐误差导致
- radar横向分辨率差导致
- 作者使用RetinaNet作为backbone
- 经过annotation filter的点云,radar-camera fusion结果涨点明显;不经过filtering的则涨点不明显。表明了去除radar noise对检测效果提升的必要性。
- 作者尝试将radar channel降为1,表明有无radar,结果显示掉点比较明显。说明radar的距离、rcs等信息对于目标检测结果有比较大的影响。
- 作者提的几个可能的研究方向
- 不基于GT实现radar noise的滤除
- 应对标定误差、时间对齐误差等的鲁棒性算法
- 本文背景仍是2d检测,考虑扩展到3d检测的可能性
进一步了解
- RetinaNet
- Blackout: Speeding up recurrent neural network language models with very large vocabularies
原文和代码
https://arxiv.org/abs/2005.07431
参考资料
无
本文由作者按照 CC BY 4.0 进行授权