快速了解一个网络:CaDDN, Categorical Depth Distribution Network
以下内容偏向于记录个人学习过程及思考,请审慎阅读。
背景
单目3d检测只需要一个camera,便宜易部署,但是3d检测效果远不如lidar、stereo相关方法,本质上是缺少了深度相关的信息。
为了解决这个问题,一些工作会单独训练一个单目深度估计网络。但是网络预测的深度在3d目标检测阶段被直接使用,未考虑到深度的不确定性,会导致3d目标检测的定位精度较差。另外,单独训练的单目深度估计网络并不一定会使得3d目标检测任务是最优的。
也有一些隐式的做法会直接将img feature变换到3d空间,再变换到bev grids。但是由于缺少显式的深度监督,会导致多个位置上的img feature是类似的,导致网络检测效果不好。
核心思想
在3d目标检测任务中,在深度方向上划分为多个bin,将深度预测显式地建模为分类任务,即预测img上的pixel/feature属于哪个深度bin,并在训练过程中用真值监督。
作者认为这种显式的、具有尖峰的深度分布监督,可以让网络的深度预测更加准确,从而提升3d目标检测任务的效果。
整个网络可以e2e的形式训练起来,从而使得深度预测任务和3d检测任务是联合训练的,保证全局最优。
Pipeline
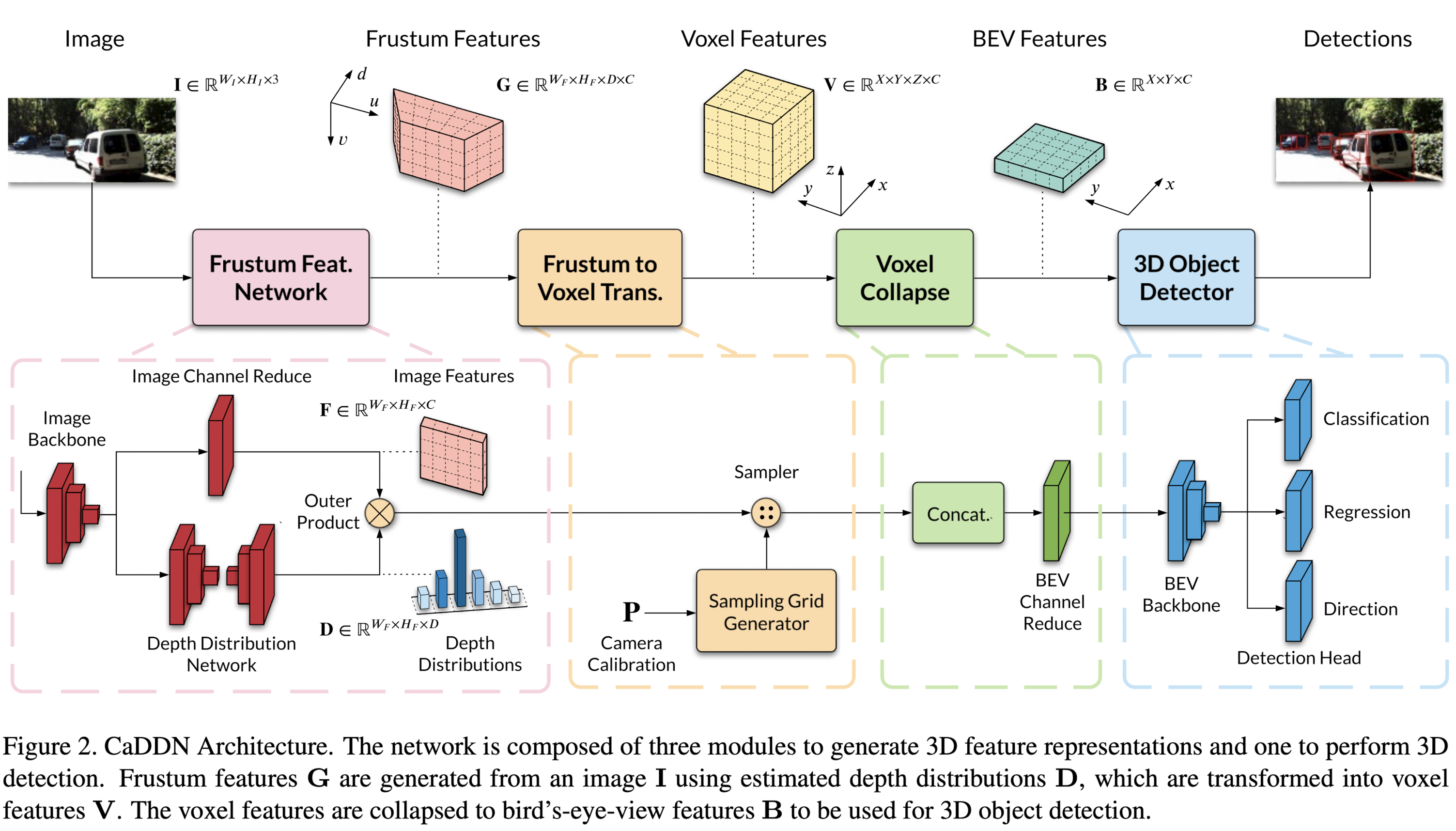
亿些细节
3D Representation Learning
总的来说,输入是img,根据估计的深度分布构造frustum features (通常翻译为视锥特征),再根据相机内外参将frustum feature变换为voxel features,然后拍扁到bev space得到bev features。
Frustum Feature Network
Image Backbone
Input: WI x HI x 3
Process: 首先使用ResNet-101作为backbone提取img features。注意这里为了获得更高的空间分辨率(更小的感受野),作者是将ResNet-101中Block1的输出作为提取的features。如果空间分辨率太小的话voxel features容易采样到很多重复的features。
Output: WF x HF x C
Depth Distribution Network
Input: WF x HF x C
Process: 对于feature map上的每个pixel,预测一个D维的深度分布,每一维代表该像素分布在对应深度bin上的概率。具体地,作者参考了DeepLabV3中上采样-下采样的思路:首先使用ResNet-101后续的Block2~4继续提取features,再连接atrous spatial pyramid pooling得到D个channel;最后再通过bilinear interpolation的方式进行上采样,得到输出。因为建模为分类问题,作者将D个channel的输出通过softmax进行归一化,得到D个概率。
Output: WF x HF x D
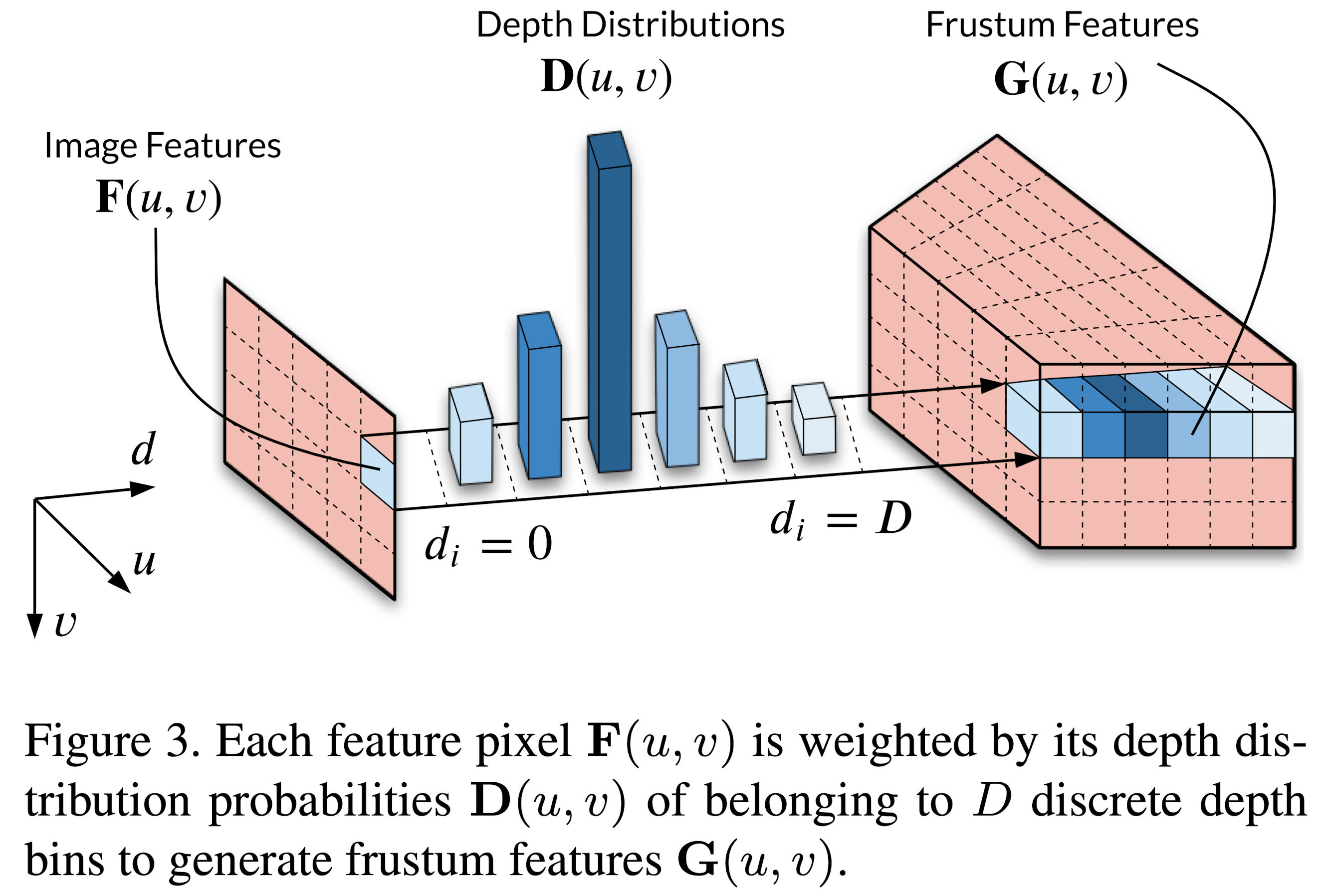
Image Channel Reduce
Input: WF x HF x C
Process: 使用1x1卷积 + BatchNorm + ReLU进行融合,将img feature map的channel数从256减少到64,减少内存。
Output: WF x HF x C
Get Frustum Features
Input: WF x HF x C + WF x HF x D
Process: 对于WF x HF中的每个C维向量,获得其对应的D维深度概率分布,加权即可得到D x C维输出(此处与LSS网络中的思路一致)。
Output: WF x HF x D x C
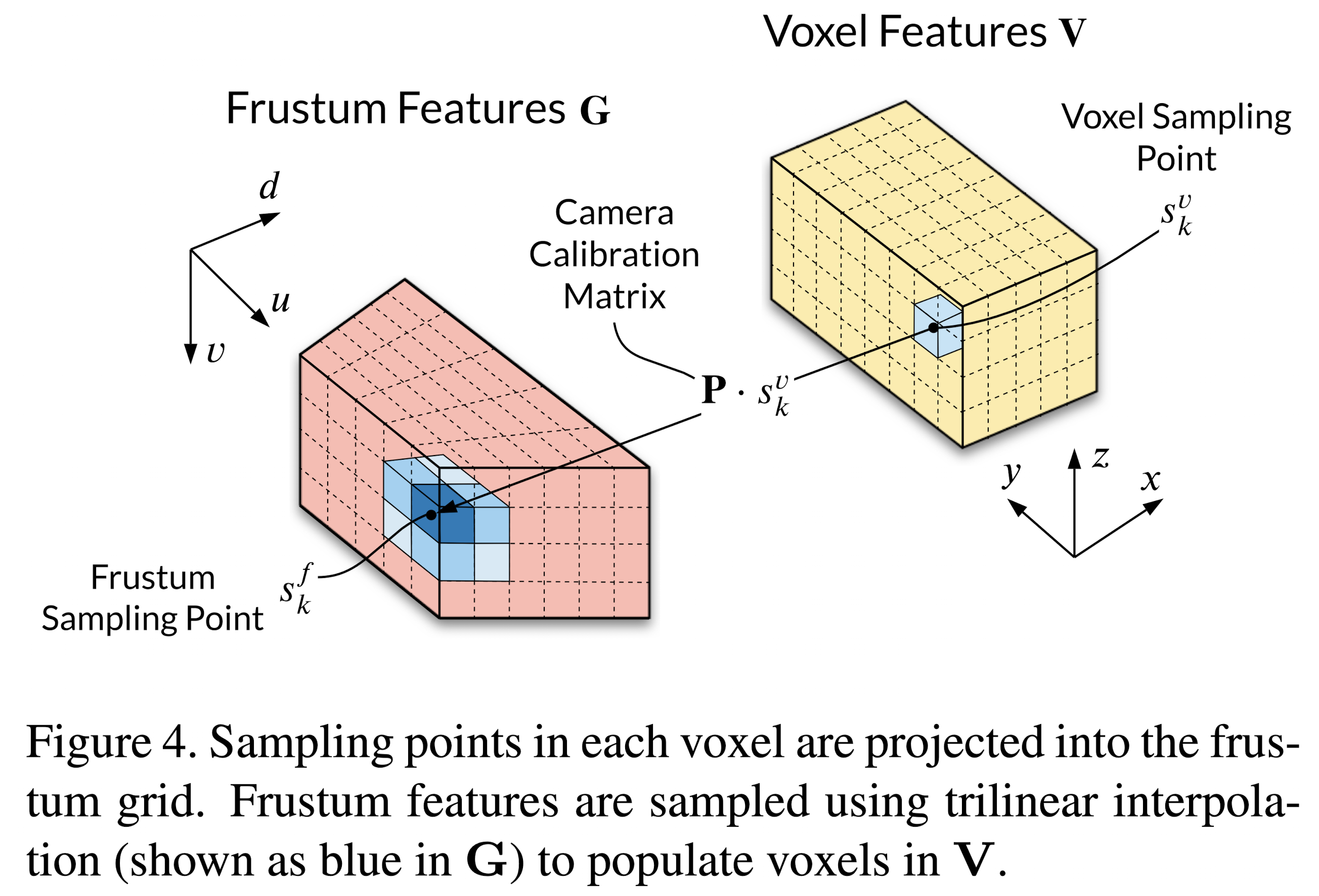
Frustum to Voxel Transformation
Input: WF x HF x D x C
Process: 将3d空间划分为不同的voxels,根据相机内外参变换可获得对应的[u, v, d],在frustum features的离散点上通过trilinear interpolation采样feature,得到voxel features。注意voxel的空间分辨率应与frustum features的空间分辨率尽量保持一致,避免重复features的出现或浪费features。
Output: X x Y x Z x C
Voxel Collapse to BEV
Input: X x Y x Z x C
Process: 将输入的最后2维concat,从而reshape为X x Y x (Z * C),再对reshape后的第3个纬度使用1x1卷积 + BatchNorm + ReLU进行融合,得到BEV features,这样就将C和Z两个维度的信息都考虑并融合了。
Output: X x Y x C
BEV 3D Object Detection
这里作者借鉴了PointPillars中对应的网络结构,但是增加了3x3 convolution + BatchNorm + ReLU layers的数量。作者认为单目中的信息远小于lidar点云中的信息,因此需要更复杂的网络结构以获得更高质量的features。
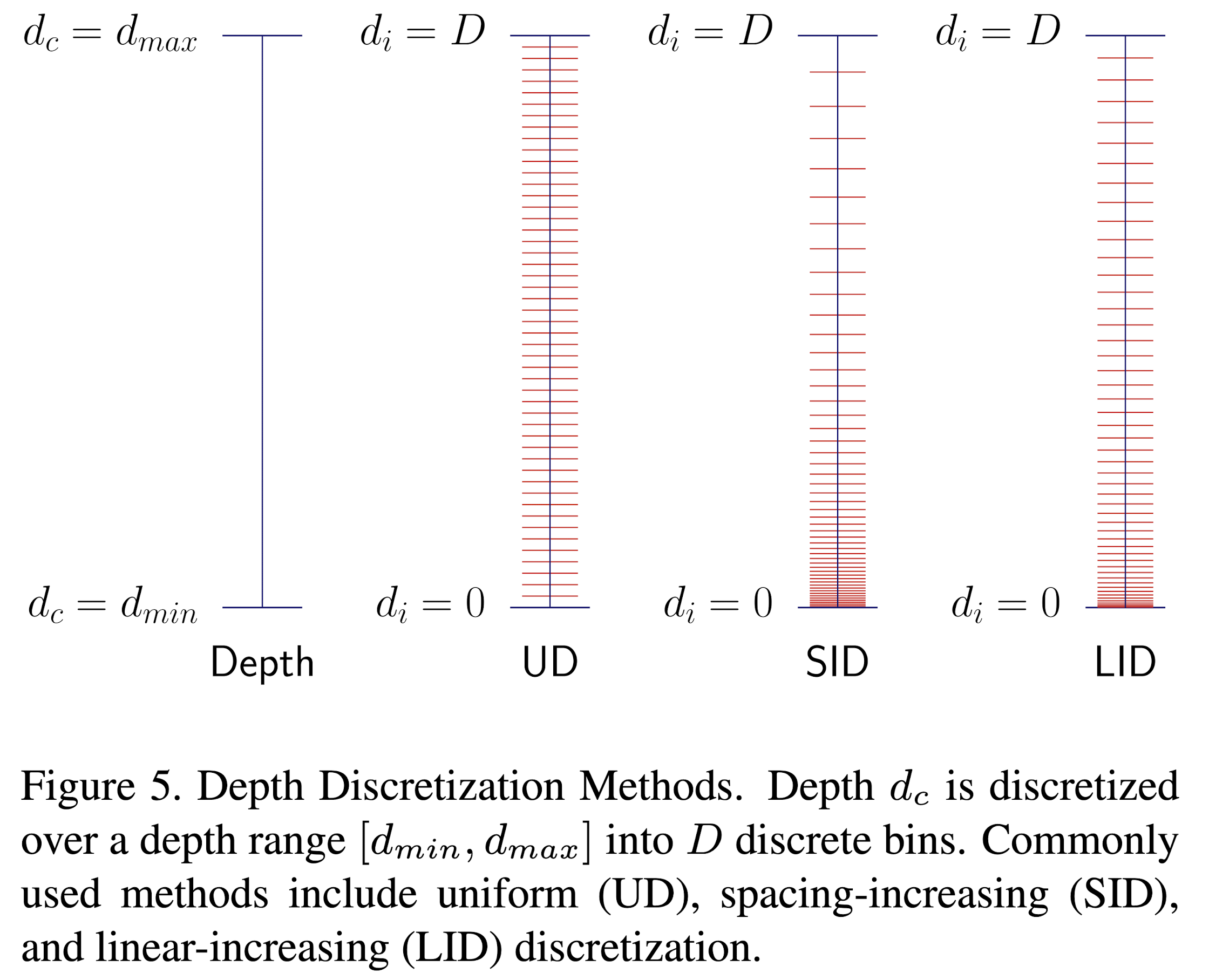
Depth Discretization
这里作者采用的是linear-increasing discretization (LID),不同的Depth Discretization方式如图
Depth Distribution Label Generation
因为需要显式的监督深度,这里作者需要获得深度分布的标签。这里作者是将lidar点云反投到image上来获得每个像素点的深度,然后进行D维的one-hot编码。
Training Losses
在整幅图像中,由于部份场景目标分布比较稀疏,背景占据了绝大多数的范围。因此,为了更好地突出目标检测任务,这里作者采用了focal loss,即对背景相关深度的监督权重较低,对目标相关的深度监督权重较高(即所有落在2d检测框中的pixel)。
最终的loss形式为深度loss + 分类loss + 位置回归loss + 朝向loss的加权求和。
Data Augmentation
horizontal flip
进一步了解
atrous spatial pyramid pooling
focal loss
原文和代码
https://arxiv.org/abs/2103.01100
参考资料
无
p.s. 这篇文章个人感觉写的非常非常好,内容细致,结构清晰,插图形象易懂,非常适合学习。