快速了解一个网络:BevDepth
以下内容偏向于记录个人学习过程及思考,请审慎阅读。
背景
作者将LSS (Lift, Splat, Shoot)网络中估计的深度进行了可视化,发现结果意外的差。
作者认为LSS网络有3大缺陷:
- 深度预测部份并非有loss直接监督,而是通过检测loss反传梯度间接训练的,因此导致深度预测效果并不好。
- 大部分像素点没有预测出合理的深度值,作者认为这些地方并没有训练的比较好,推断深度预测部份的泛化性应该不会很好。
- 由于深度预测的不准确,在变换时会导致后续的frustum features、bev features都只能取到部份的fv features,影响模型性能。
作者尝试将LSS中的深度预测部份输出替换为Lidar点云的真值深度,发现模型性能大幅提升。因此可以说明深度预测的准确度对于3D目标检测任务而言至关重要。
因此提出本文的网络:BevDepth
核心思想
- 利用Lidar点云生成真值深度,在训练过程中显式的监督深度预测loss
- 将相机内外参encode作为深度预测网络的输入,预期提高网络对不同相机内外参的泛化性
- 提出一个深度精调的网络结构,用于精调预测的深度(个人感觉有点凑数,这个模块对于检测效果的作用也不是很显著)。
- 其他贡献:Efficient Voxel Pooling & Multi Frame Fusion,前者利用并行性提高训练和计算效率,后者利用多帧信息融合到当前帧加强feature实现涨点。
Pipeline
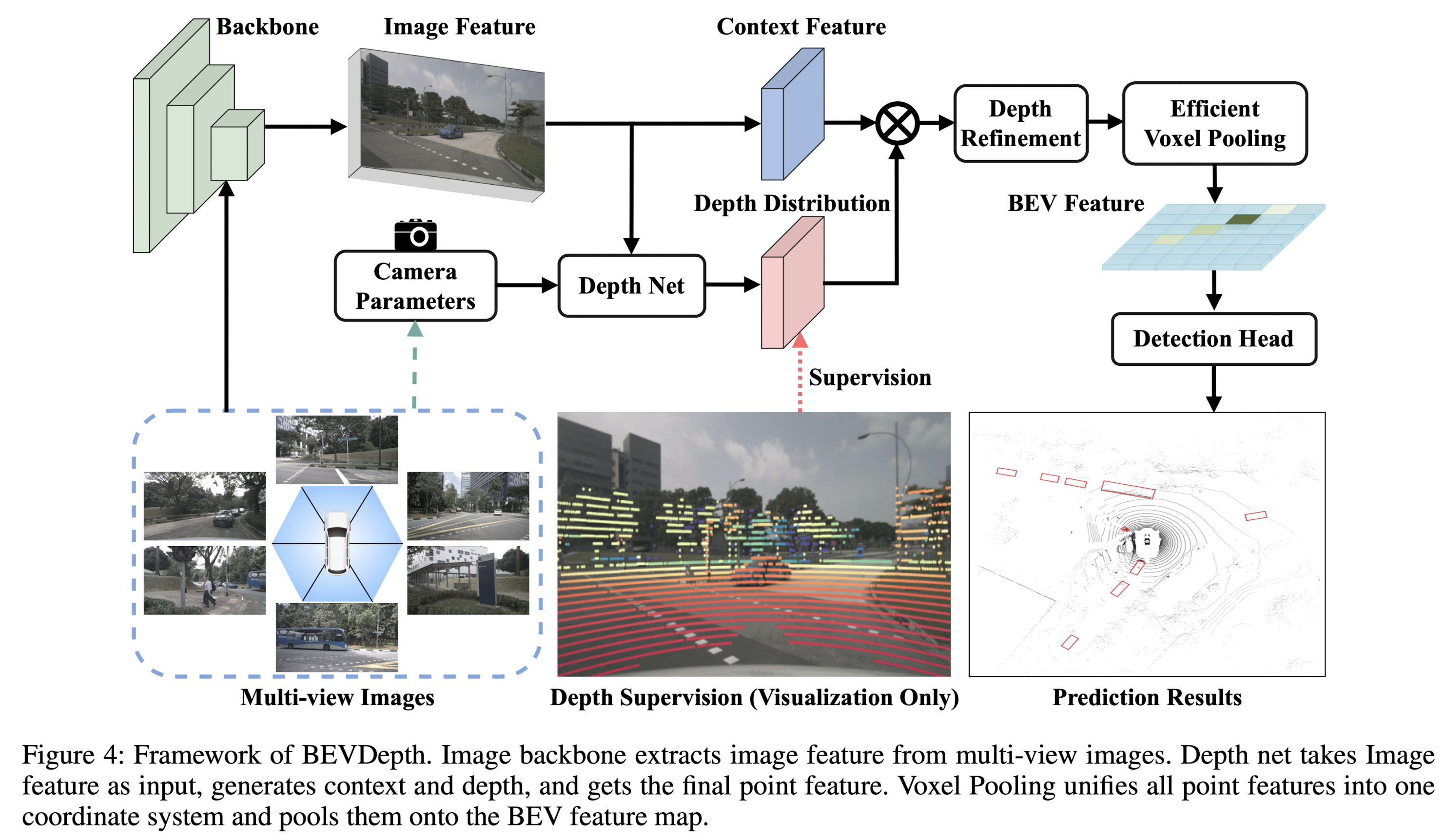
亿些细节
深入分析LSS中的深度预测部份
让LSS工作非常简单,但让LSS工作好非常困难。
Making Lift-splat work is easy
这里作者做了个试验,将LSS中的深度预测替换为随机值,并在后续的训练和测试中冻住。
作者发现这种做法并没有引起太多的掉点。
这个试验表明,因为即使是随机的深度分布,仍然有正确的深度被激活时,从而获得一定的检测能力。
Making Lift-splat work well is hard
- 当网络没有直接关于depth的loss时,网络只是通过部份的深度学习对目标进行检测。
- 作者试验发现大部分像素没有被学习到正确的深度,因此推测网络的泛化性必然不足。作者尝试使用不同的img size和相机参数时,发现原LSS网络掉点比较严重。
- 由于深度不准确,导致通过aggregation获得bev features,只能通过部份/不完整的img features,影响后续的模型性能。
BevDepth
Explicit Depth Supervision
这里作者引入了显式的深度监督。而深度的来源是将Lidar点云通过相机内外参反投到img上,取min pooling + one hot作为深度真值。
Camera-aware Depth Prediction
在相机模型中,相机的内外参对于深度的学习至关重要。因此这里作者考虑将相机参数也encode作为深度预测网络的输入。
具体是将相机内参通过MLP scale up到features,然后利用一个SeNet模块去re-weight img features,最后将相机外参concat在一起以使DepthNet获得ego系的一些感知信息。
Depth Refinement Module
这里作者是将3D voxel features CF x CD x H x W reshape成 (CF x H) x CD x W,然后在CD x W平面进行卷积,以获得沿着深度方向上的features aggregation,期望可以对深度的预测进行调整和优化。
Experiments
Efficient Voxel Pooling
作者对每个frustum feature assign一个CUDA线程,用于计算其对应的bev grid features,充分地利用了GPU的并行计算能力,大大提升了训练速度,值得学习。
Multi-frame Fusion
将历史多帧的frustum features通过外参变换到当前帧,合并作Voxel Pooling,消除ego运动到影响,有利于积累features。
进一步了解
SeNet: Squeeze-and-Excitation Networks
MVSNet: Multi-View Stereo Network
原文和代码
https://arxiv.org/abs/2206.10092
参考资料
无